
Batch Normalization
Batch Normalization
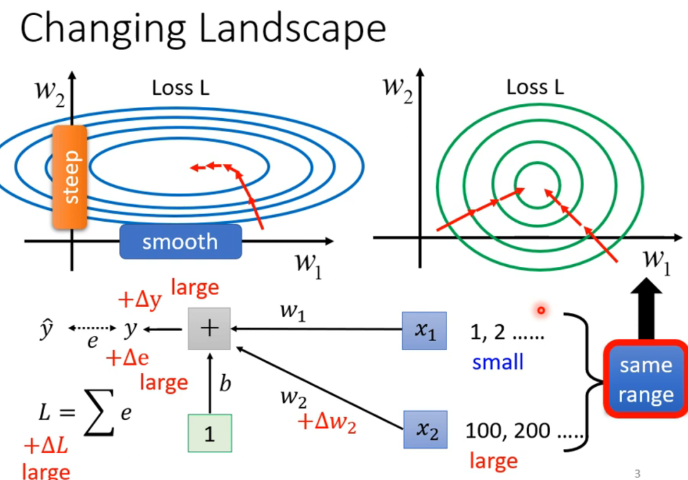
为什么会难训练
一种可能是,不同参数的斜率差别很大,导致learning rate设小设大都不好。
比如:当和数值范围差异很大时,就会导致,出现上述情况。
Feature Normalization
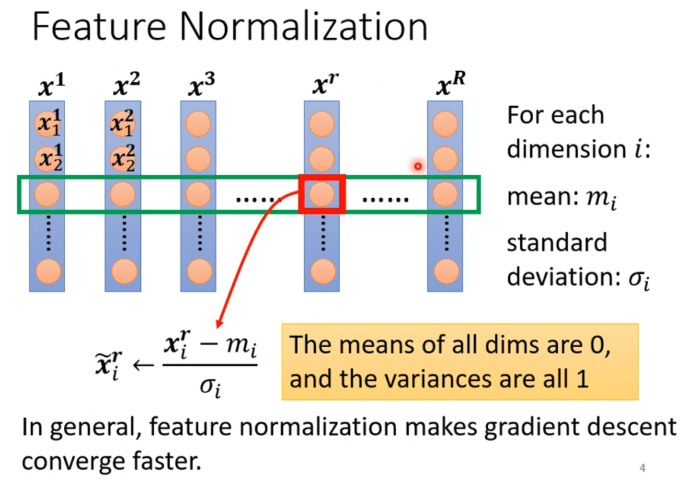
对数据集的每一个维度(特征)进行Normalization。保证不同维度的原始数据不会差异数量级。
同时我们也希望对中间输出的结果进行normalization,因为输出的结果也会被当做input去处理训练新的参数。
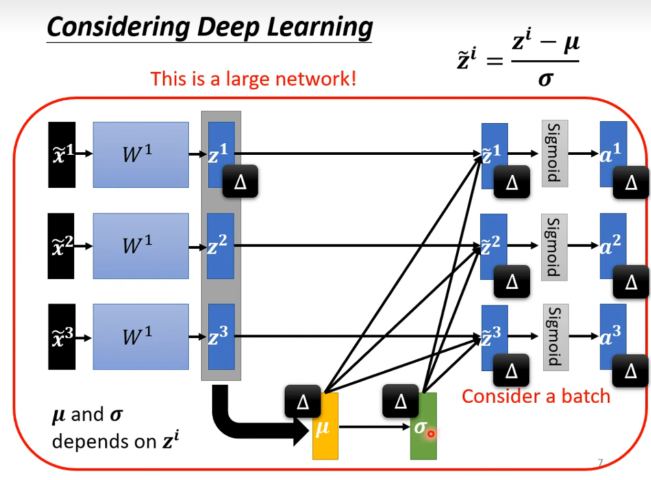
实际上,一旦我们最数据进行了Normalization,那么这些数据接不能独立计算了,他们被耦合成了一个整体。但是如果把所有数据一下拿去训练,显存会爆。
于是我们采用batch的形式,比如一次训练64组数据,对这64组数据形象normalization处理区更新参数。
使用batch normalization适用于batch size比较大的时候,因为要算均值和标准差。
在实际中,我们还会加上一个参数和,来控制normalization的幅度和偏移。来避免normalization带来的副作用。于是让模型去同时学习和。(一般初始值都是1)
Batch normalization – Test
如果不到一个batch size就需要inference该怎么办呢?
在训练时,记录随时更新的均值和方差,然后在测试时使用这个均值和方差。

Batch normalization – performance
可以发现,加入标准batch normalization可以加速训练,但是时间给够的情况下最终结果差不多。
当把learning rate调大,既加速了训练,又提高了最终结果。因为使用batch normalization技术后,loss会变的相对平滑,很好训练。
BN如何work

一篇论文解释为,batch normalization可以让error surrface变的更平滑,从而加速训练。同时也认为有很多种方法不必要batch normalization就可以做到这点。因而认为影响might be somehow serrendipitous.