Ensemble
Ensemble
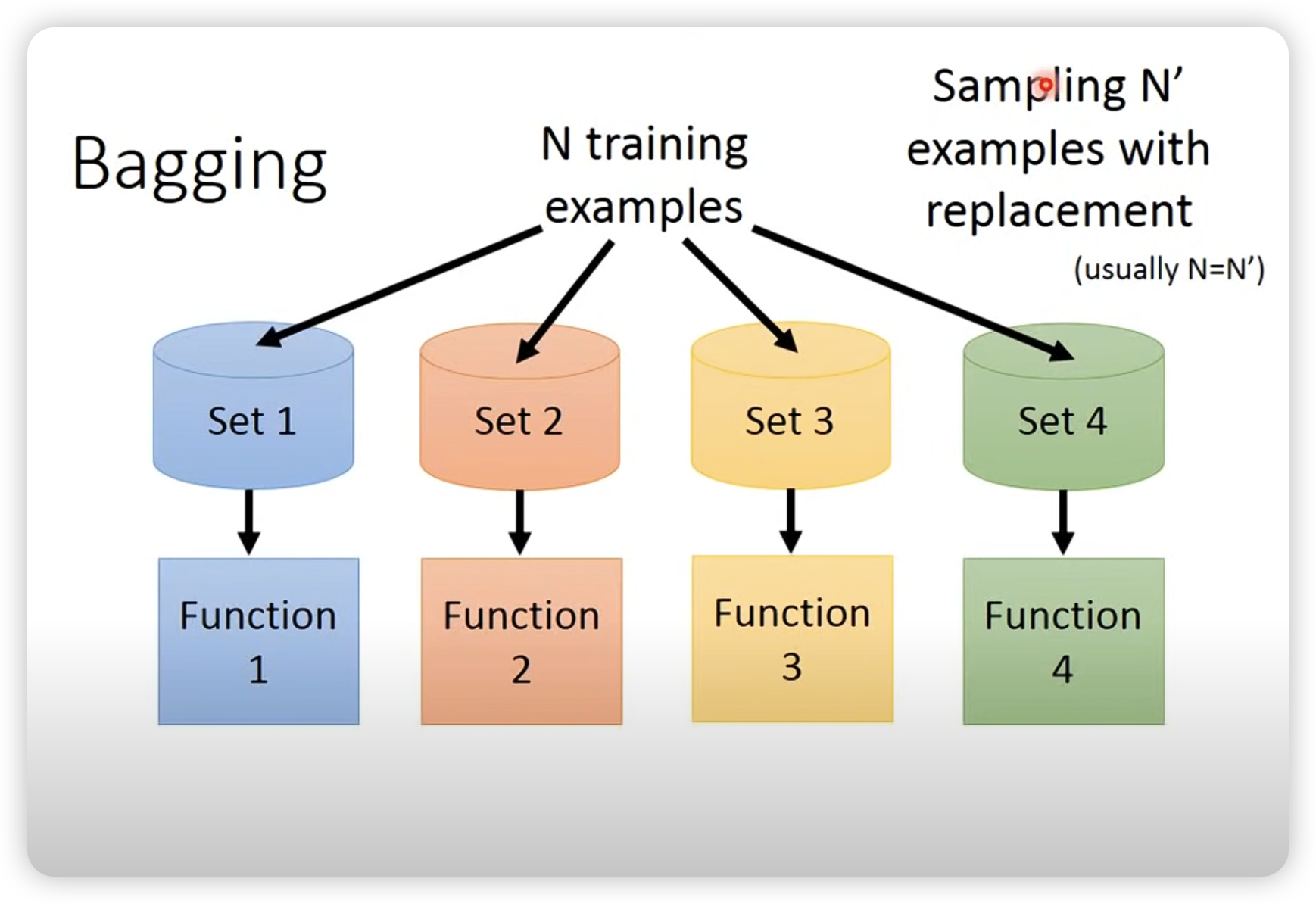
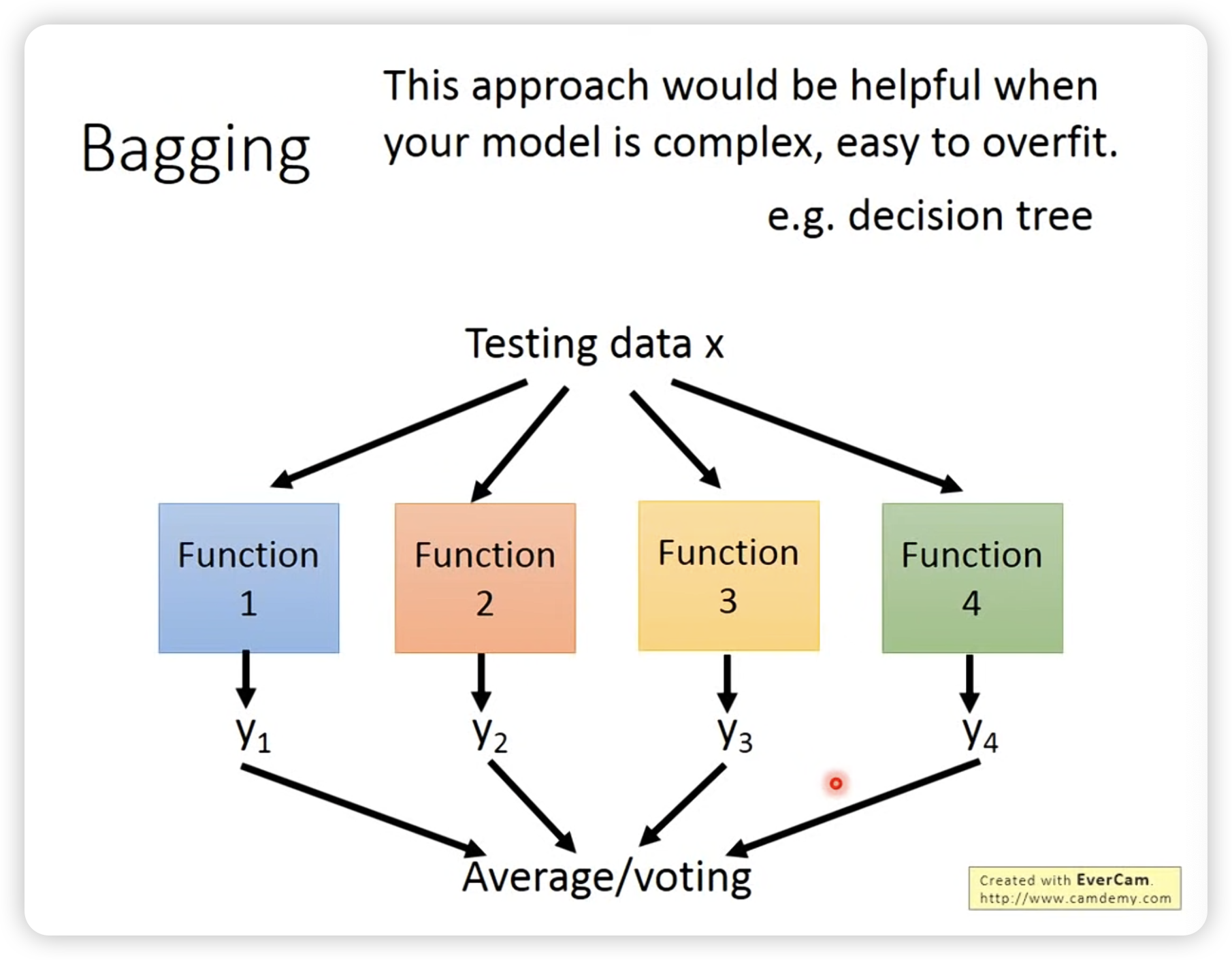
Bagging
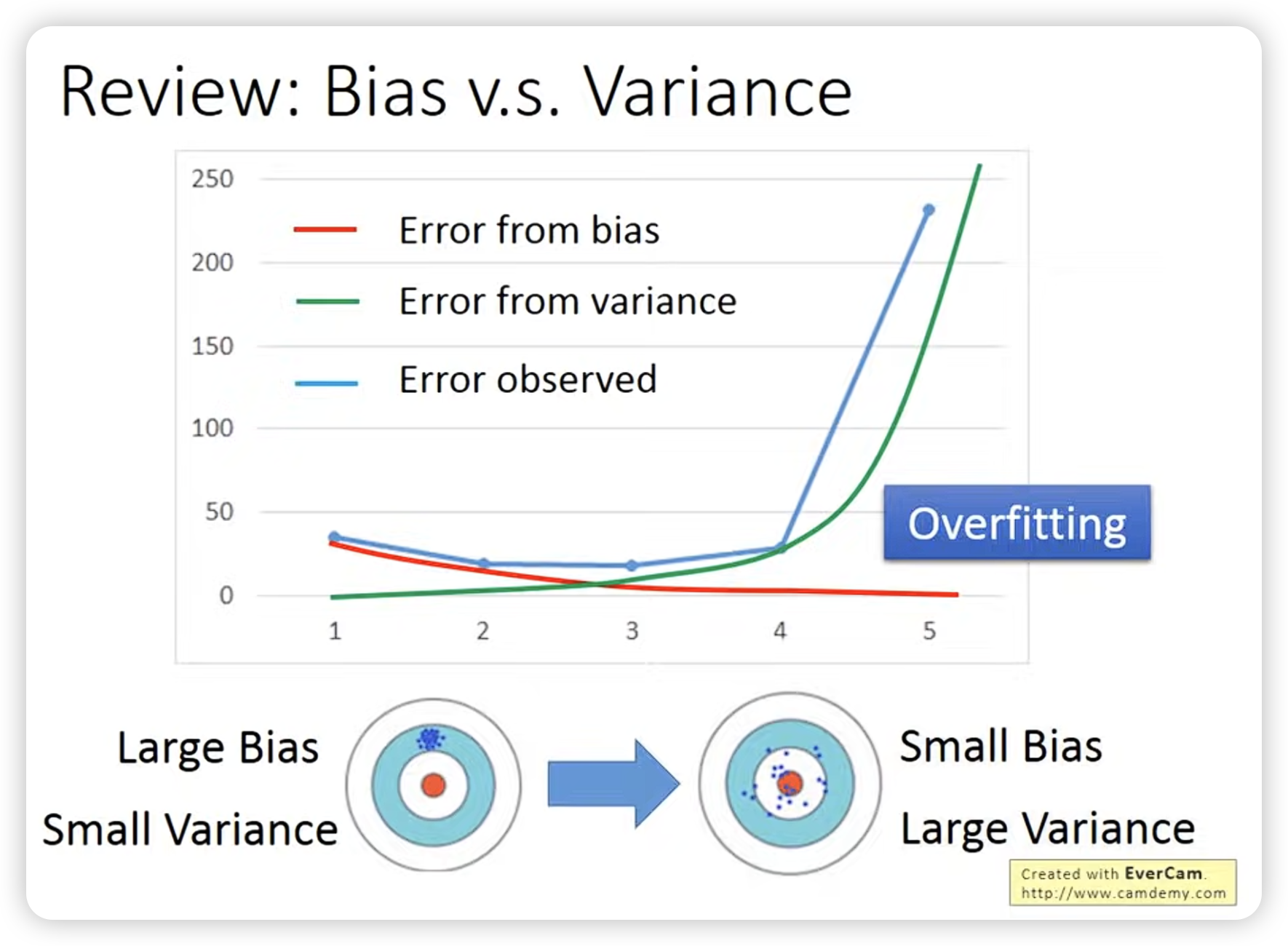
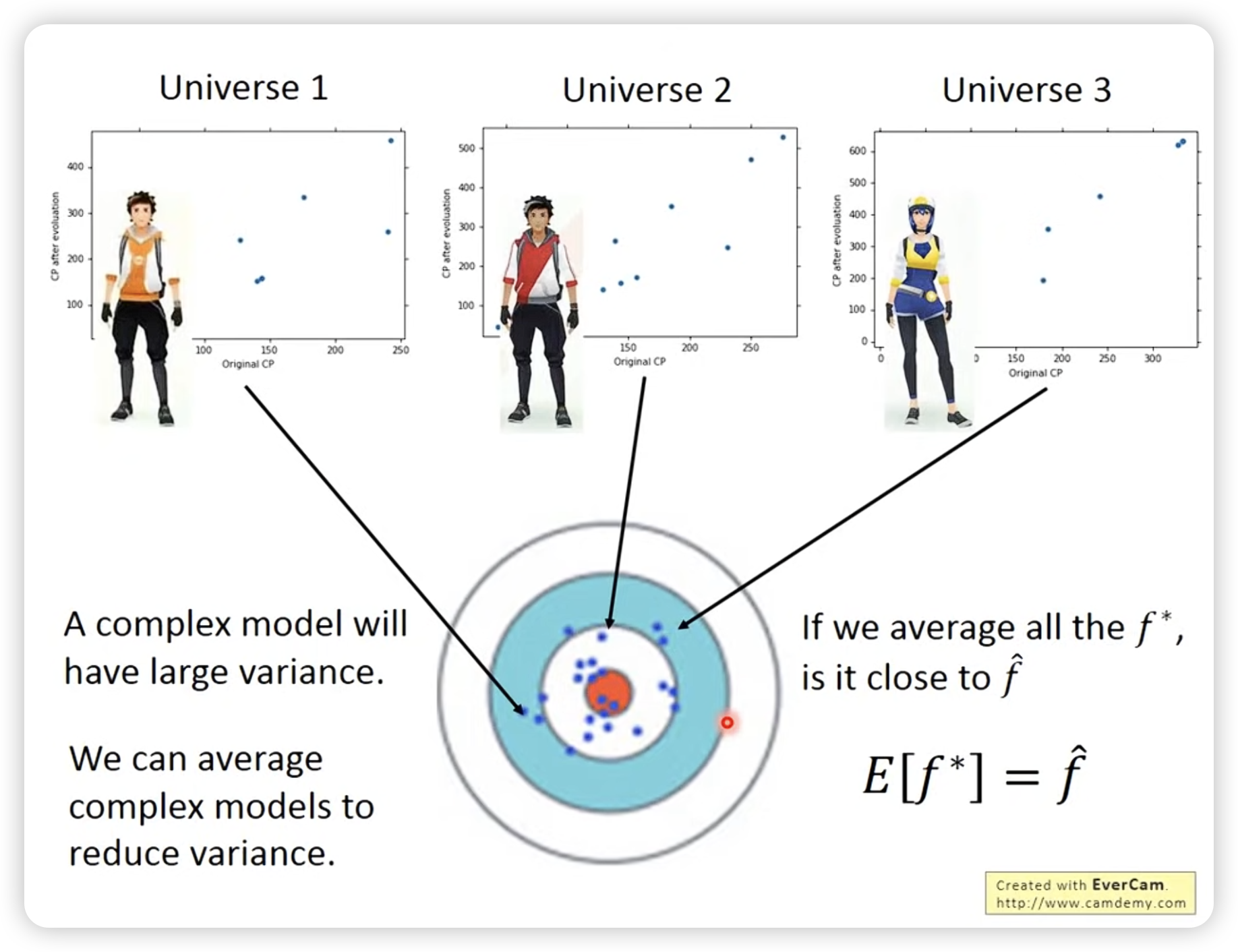
Bagging: 通过多次采样,然后平均结果,可以减小variance。
测试的时候把不同function的结果做平均(回归)或者voting(分类)。
做bagging的目的是为了减低模型的variance,所以一般是在模型比较复杂,很容易ovetfit时使用
nn其实没有那么容易overfit,decision tree其实容易overfit。
可以看到决策树考虑的东西很多。
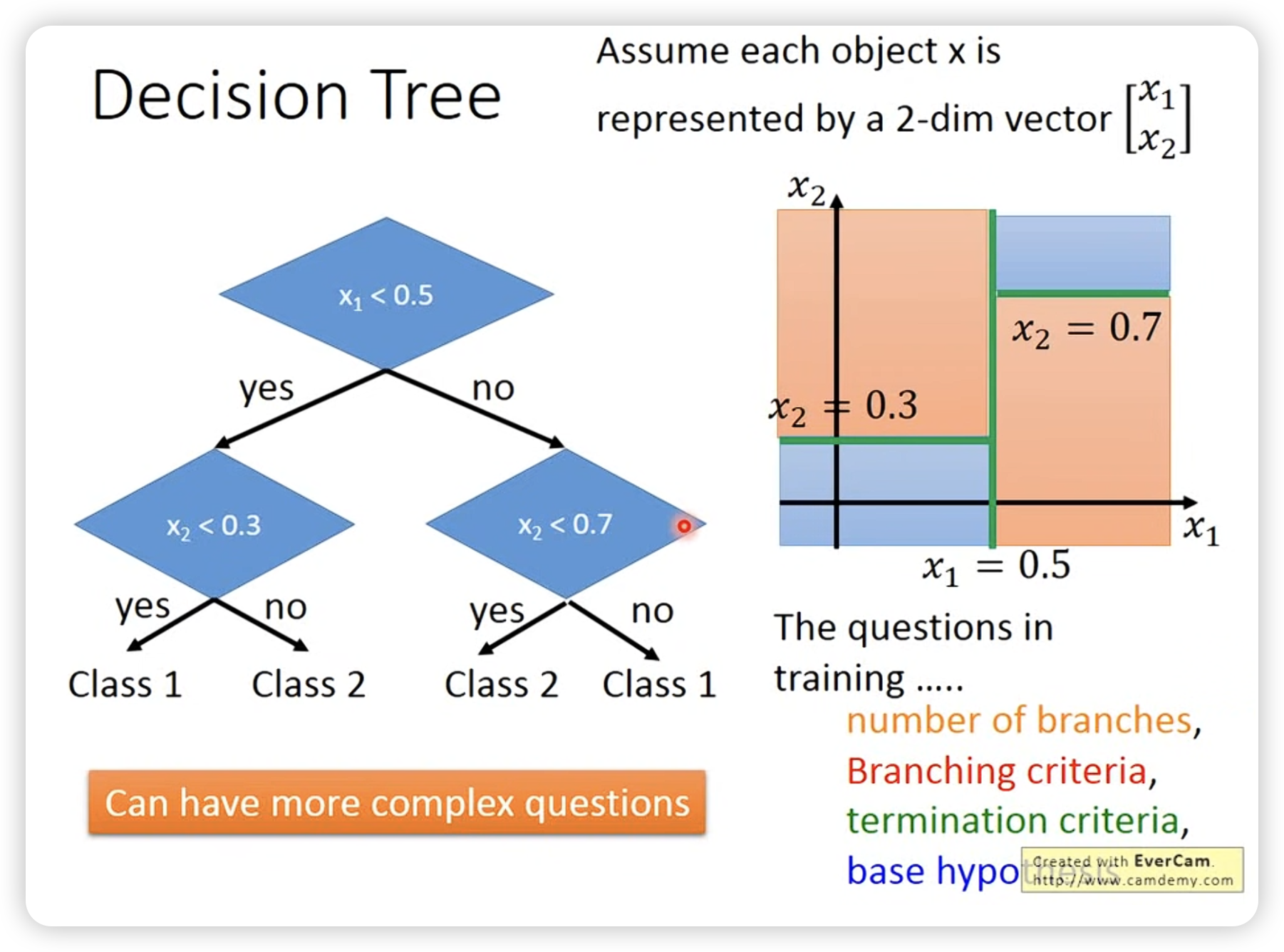
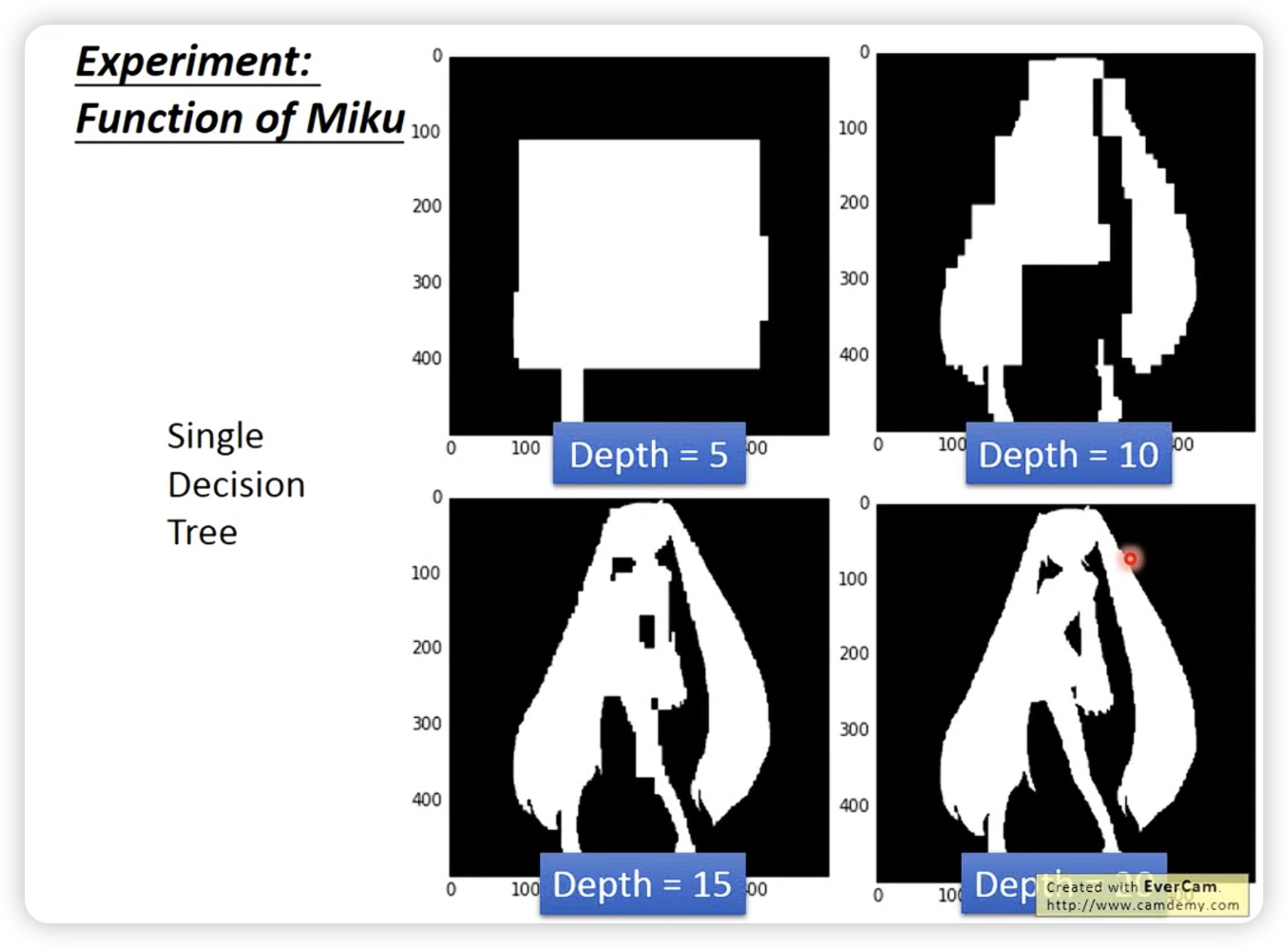 树够深,就可以作出很复杂的决策。
树够深,就可以作出很复杂的决策。
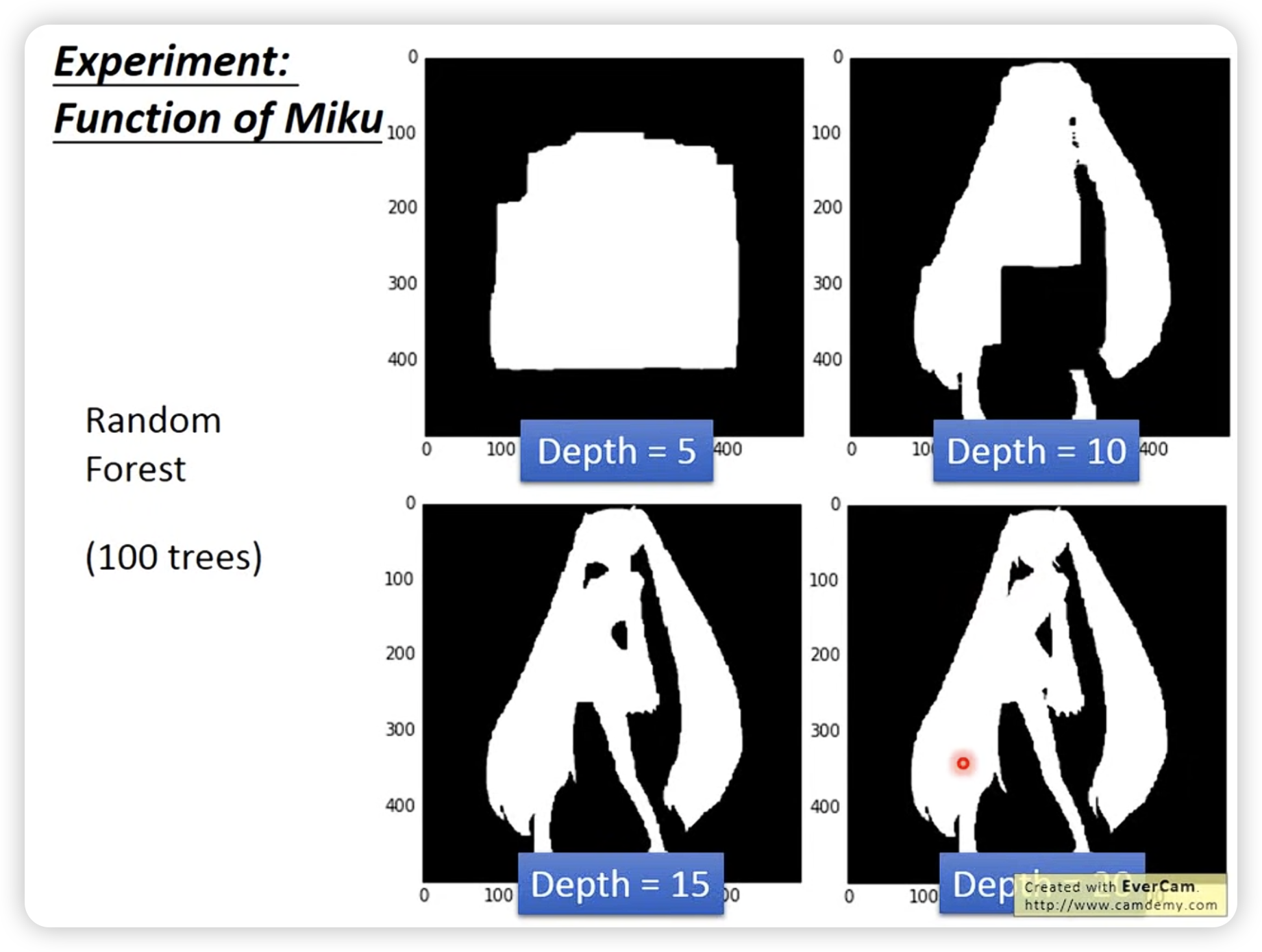
可以用random forest来增强。
这里提到一些小技巧:

- bagging可以随机放回的抽取每个树的训练样本,也可以限制一些特征让每个树的形态不一样。
- validation可以像图中一样tricky,可以不用设置显性的validation set。
random forest可以让结果更平滑,不是简单的增强,比如depth=5本来就拟合不好,那么random forest也拟合不好。但是可以让图片平滑,不像minecraft那样的方块世界。
Boosting
和bagging不同,bagging是用在很强的model上,boosting是用在很弱的model上。
当你有一些弱的model,但是不fit时,就可以用boosting。
boosting是有顺序的,先有f1,再有f2,f3,f4…

可以通过改变数据的weight从而创造新的different的training data。

Adaboost的思想: 通过改变数据的weight,让新的model关注之前model没有关注的地方。

改变weight形成新的data,使得新model的weight下老的model acc为0.5(随机)。(相当于答对加权重,答错减权重)

实际上怎么做reweight这个事情呢?

再数学随便算一下,得到参数d1,使得新的model的weight下老的model acc为0.5。

Adaboost algorithm流程:

 最后aggregate的时候,还是要加一个权重取平均结果。(直觉上也是错误率低的model有更大的权重)
最后aggregate的时候,还是要加一个权重取平均结果。(直觉上也是错误率低的model有更大的权重)
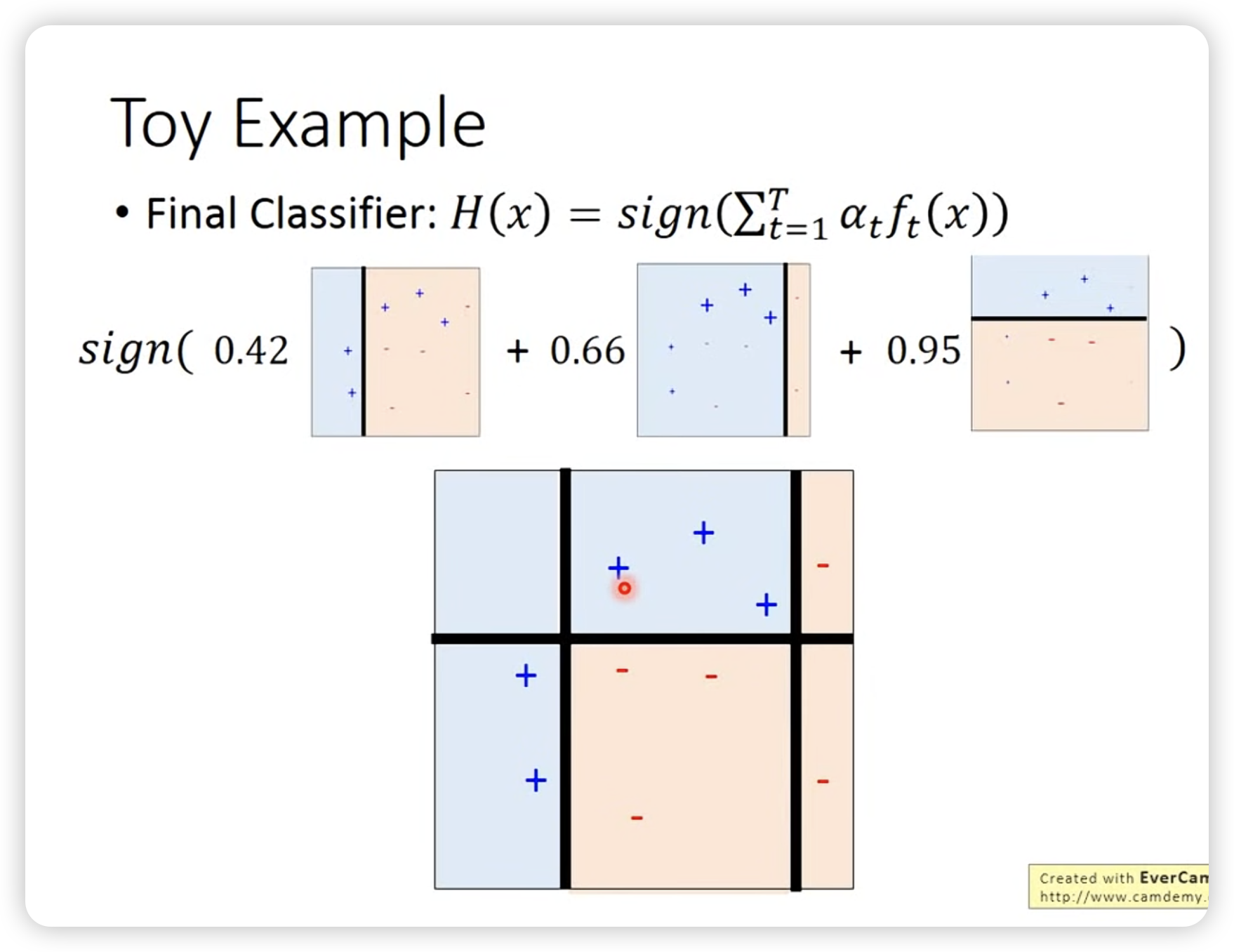
一个简单的例子:
接下来讲一下理论上的证明,为什么每次iteration后,ensemble结果会更好。

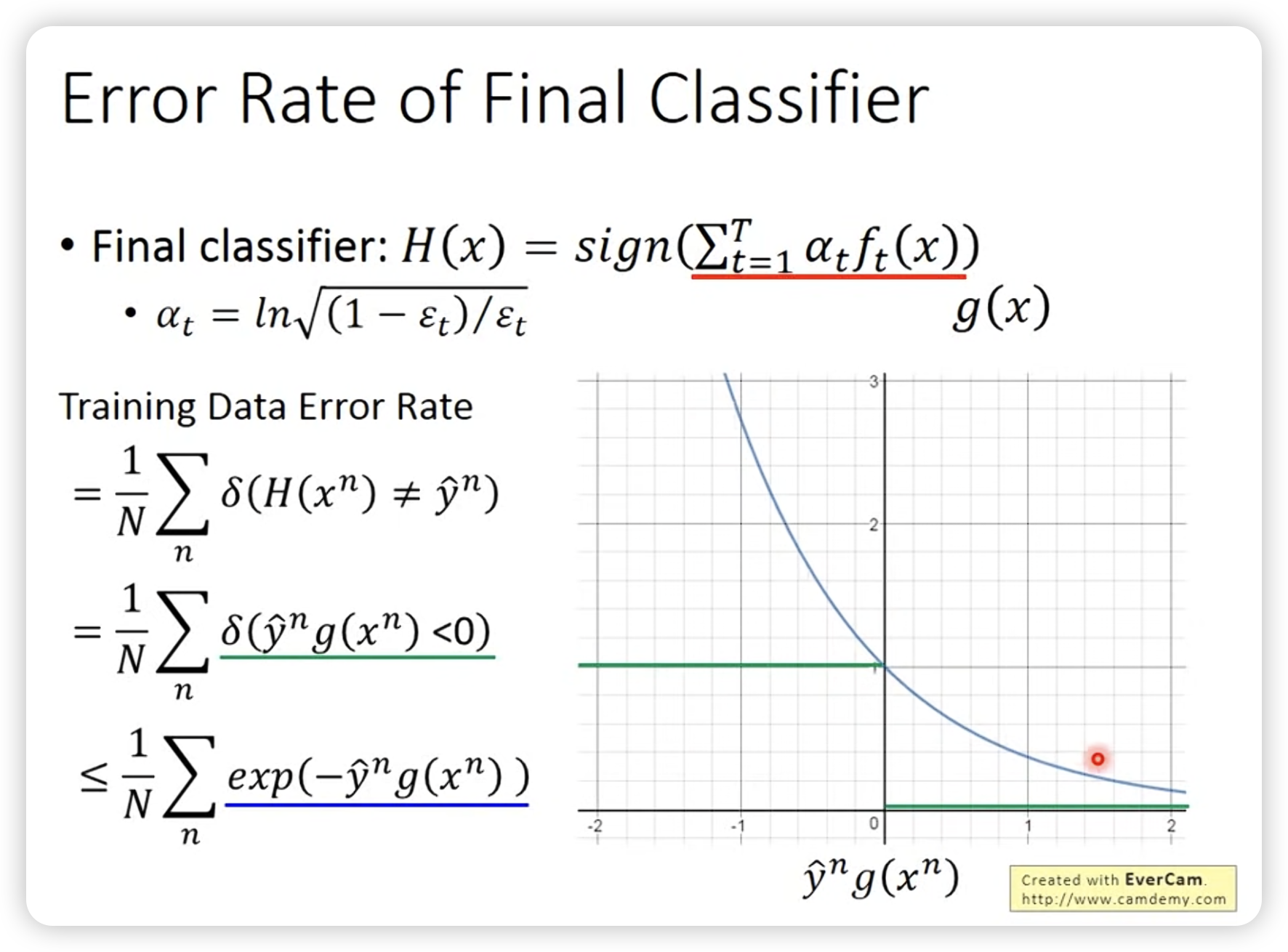

err的upperbound推出来其实就是。
所以接下来等价证明weight的summation会越来越小就好了。

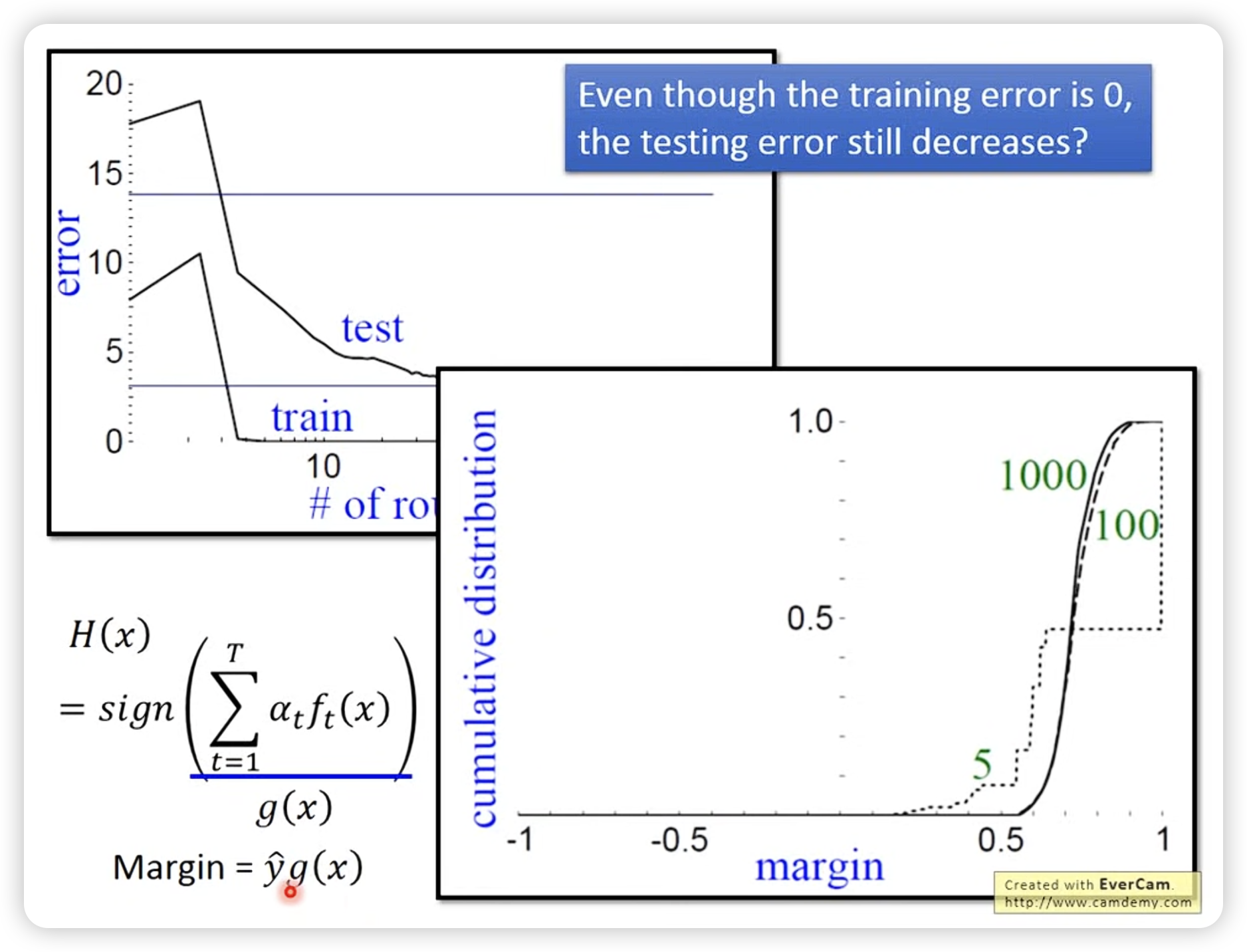
有时候在train data上已经无误了,但是增加iteration仍然可以减小test error。一部分原因是因为margin,可以看图,5次时分布在0周围多一些,当次数提升时,sign函数传入的绝对值更大,效果更好。
为什么adaboost可以让margin变大呢?
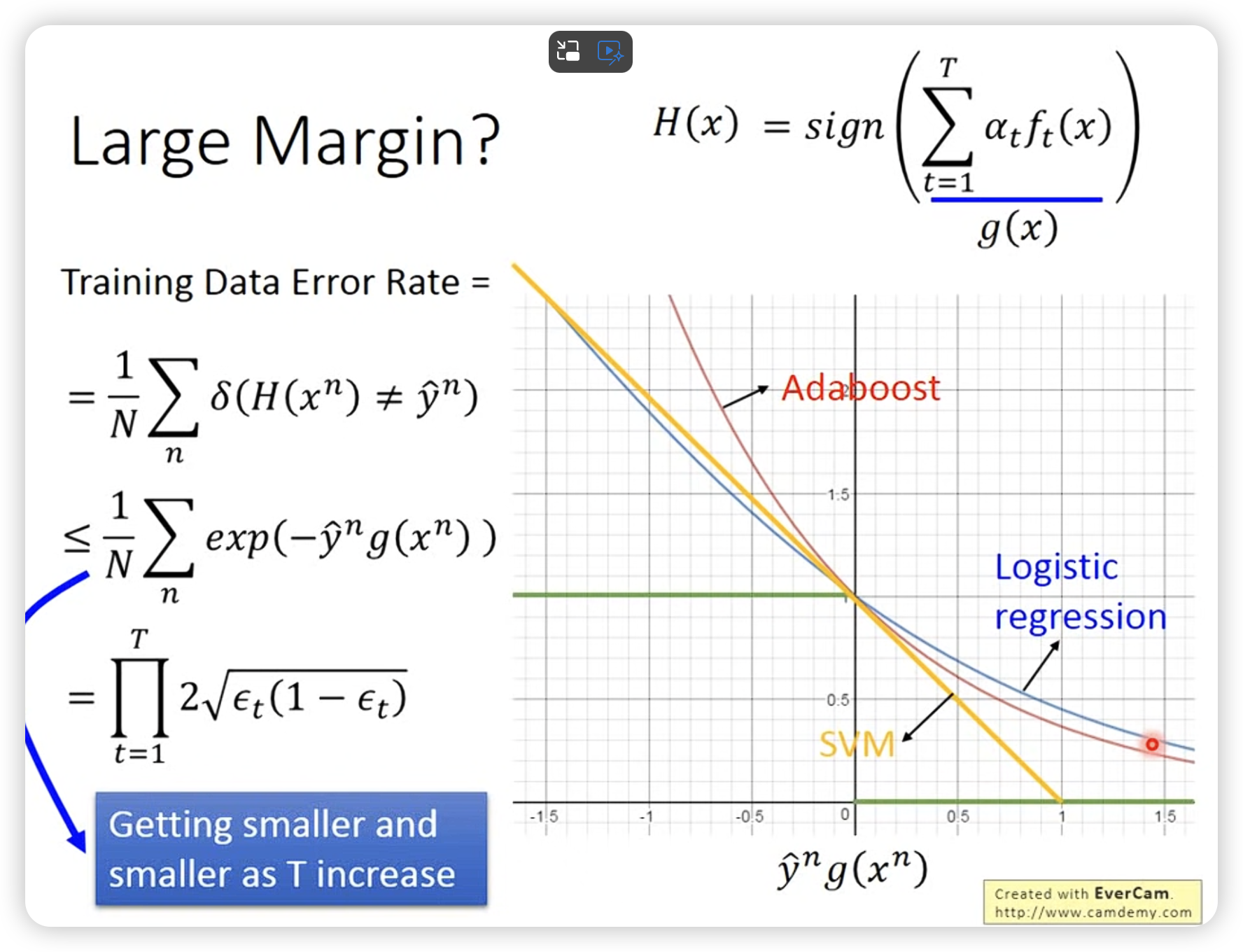
和logistic regression一样,即使没有error rate了,继续按照梯度做可以让margin变大。
结果展示:
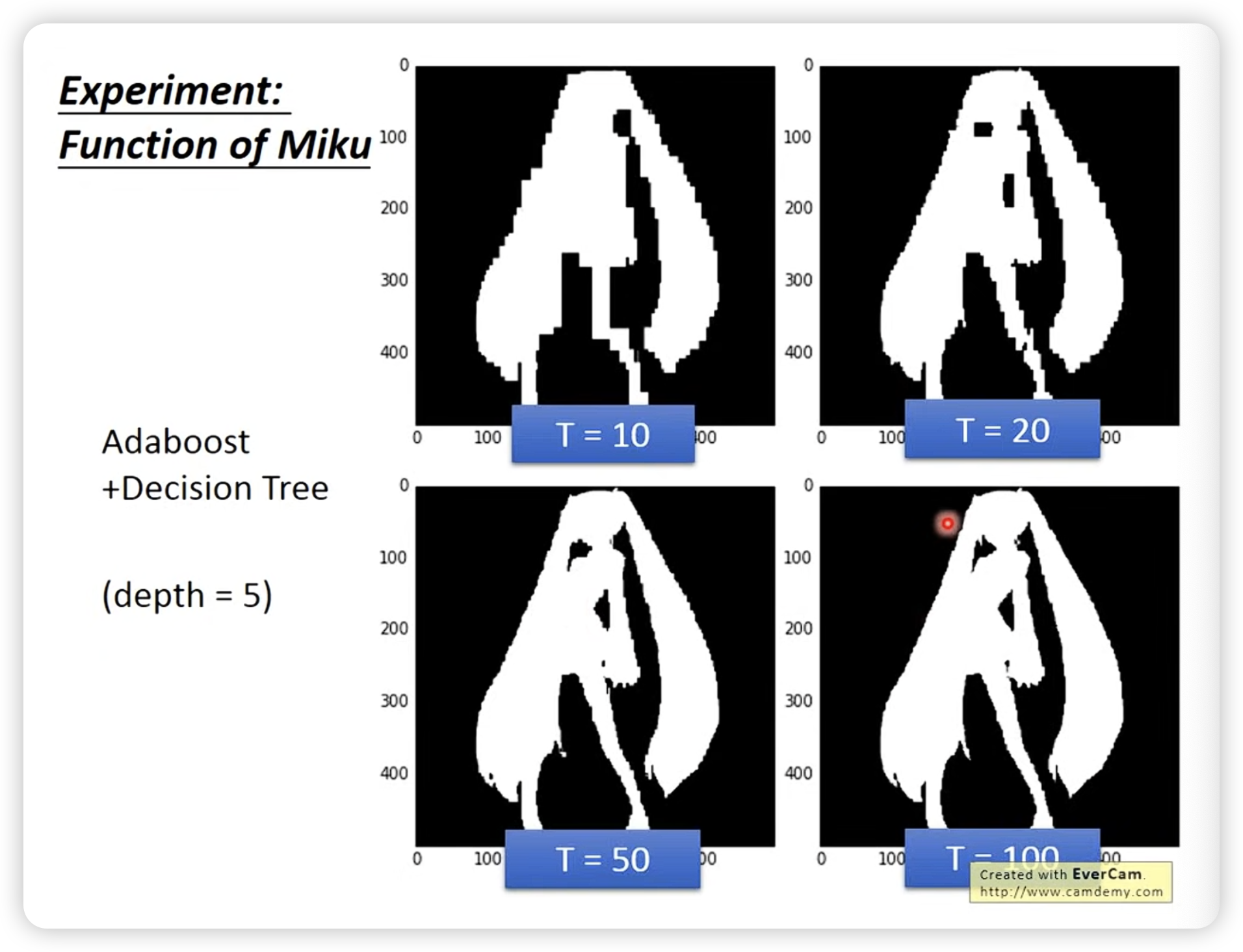 即使只有depth 5,但是boosting每次是互补的,所有也能做到很好的效果。(对比bagging根本depth5学不起来)
即使只有depth 5,但是boosting每次是互补的,所有也能做到很好的效果。(对比bagging根本depth5学不起来)
- Gradient Boosting

这里是function g对L做gradient descent。
广义上,一个函数所有点值就是这个function的参数。


这里找计算一次计算量较大,所以我们选择硬找一个最好的值,让loss掉的越多。
巧合的是,算出来就是原来方法的结果:
这里与之前的设定达成了统一。
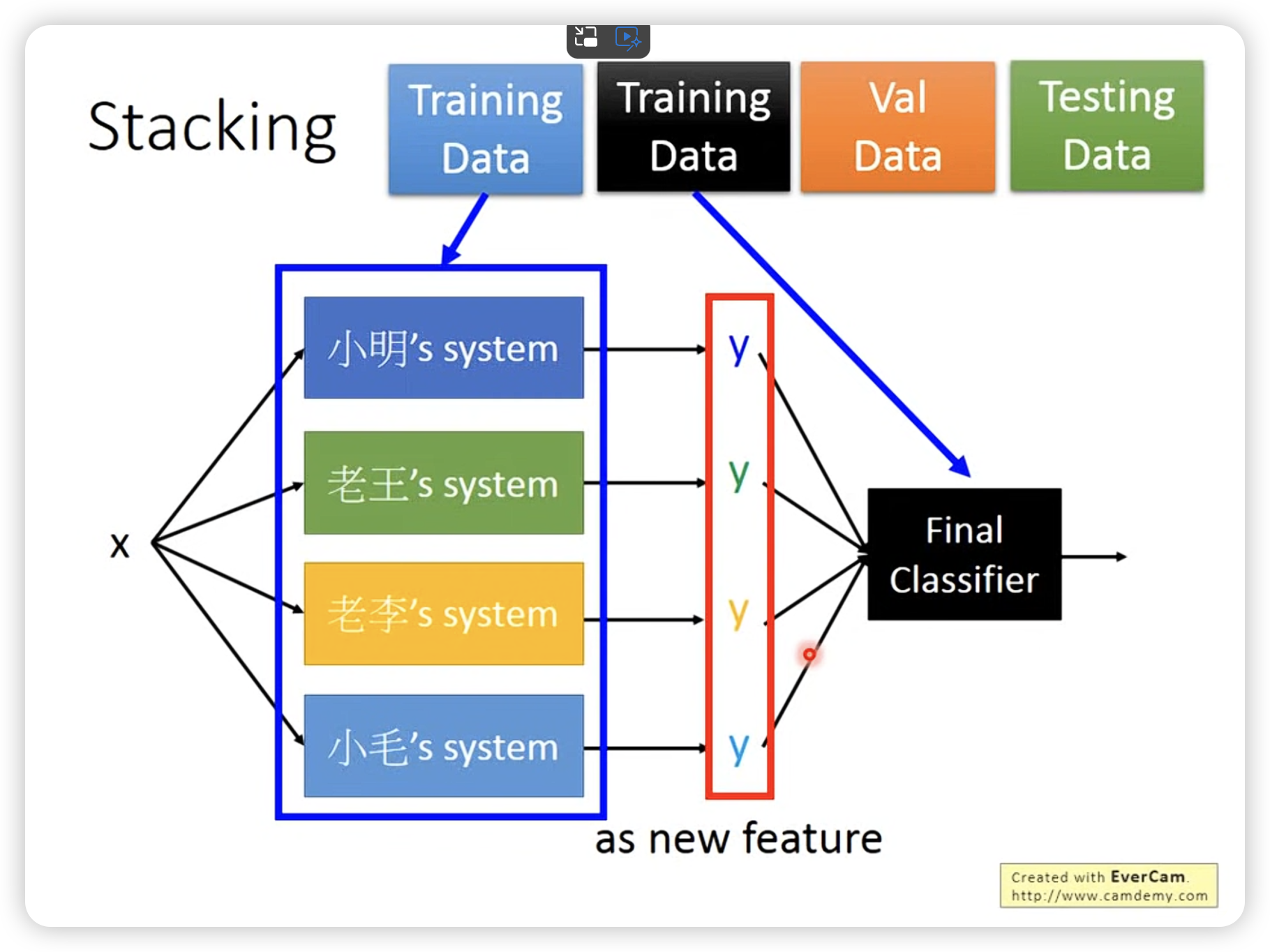
Stacking