
Network Compression
Network Compression
网络压缩是指通过减少模型的大小和计算量来提高模型的性能。这个技术在移动端和嵌入式设备上(即resource-constrained的时候,比如手表,无人机)非常有用,因为这些设备的计算资源有限。网络压缩的方法有很多,比如剪枝、量化、知识蒸馏等。

Network Pruning
去评估参数和神经元。
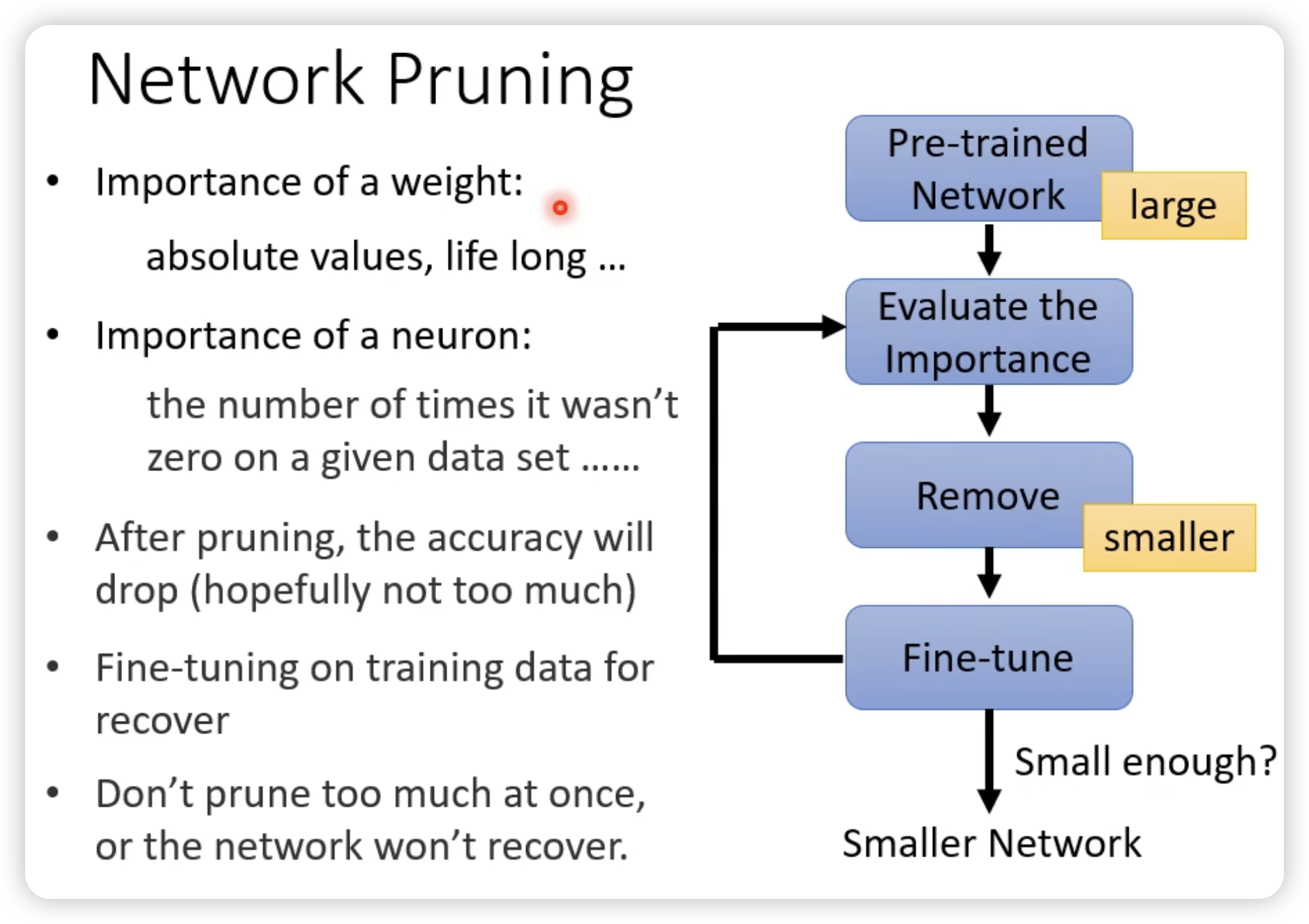
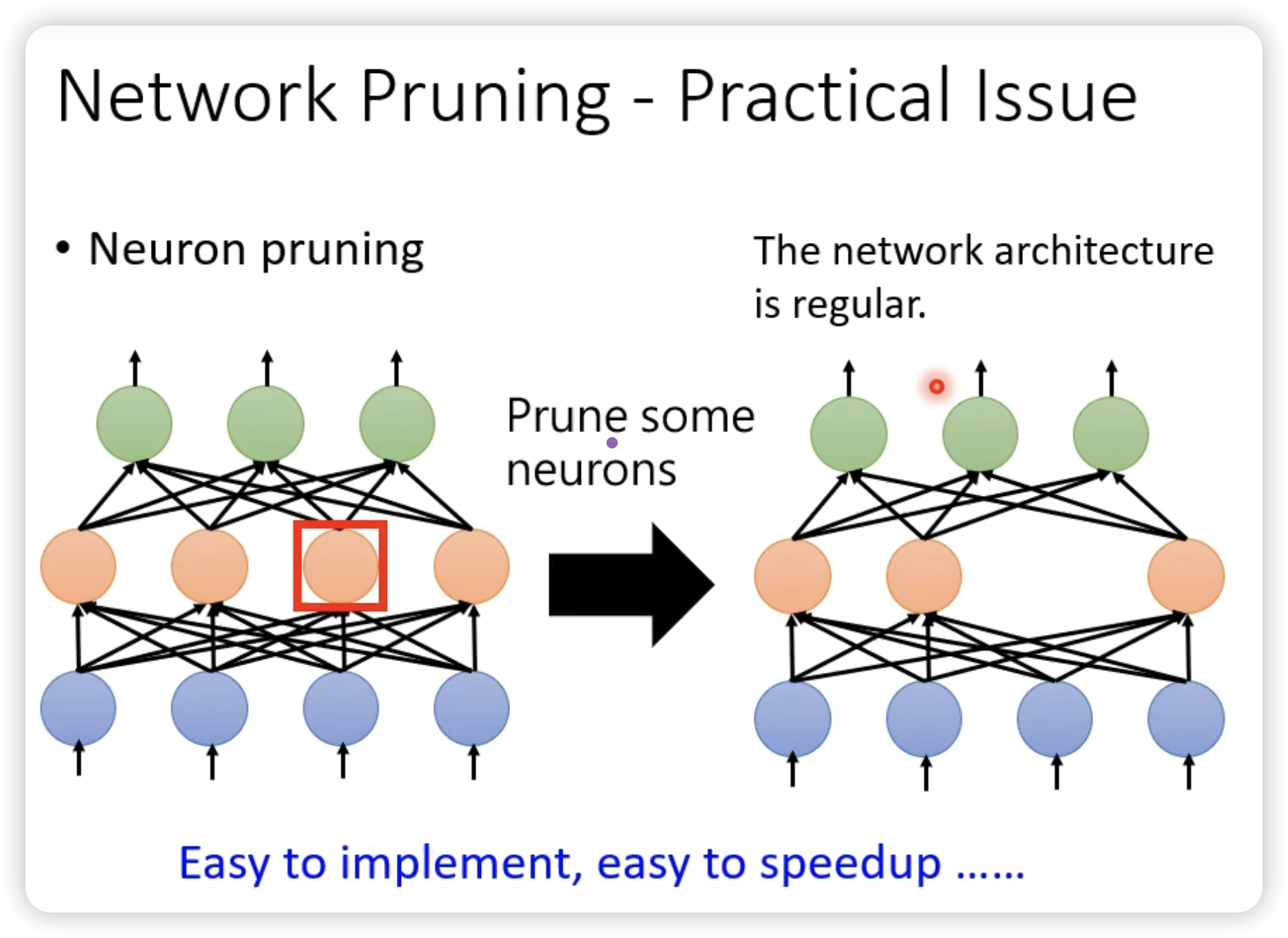
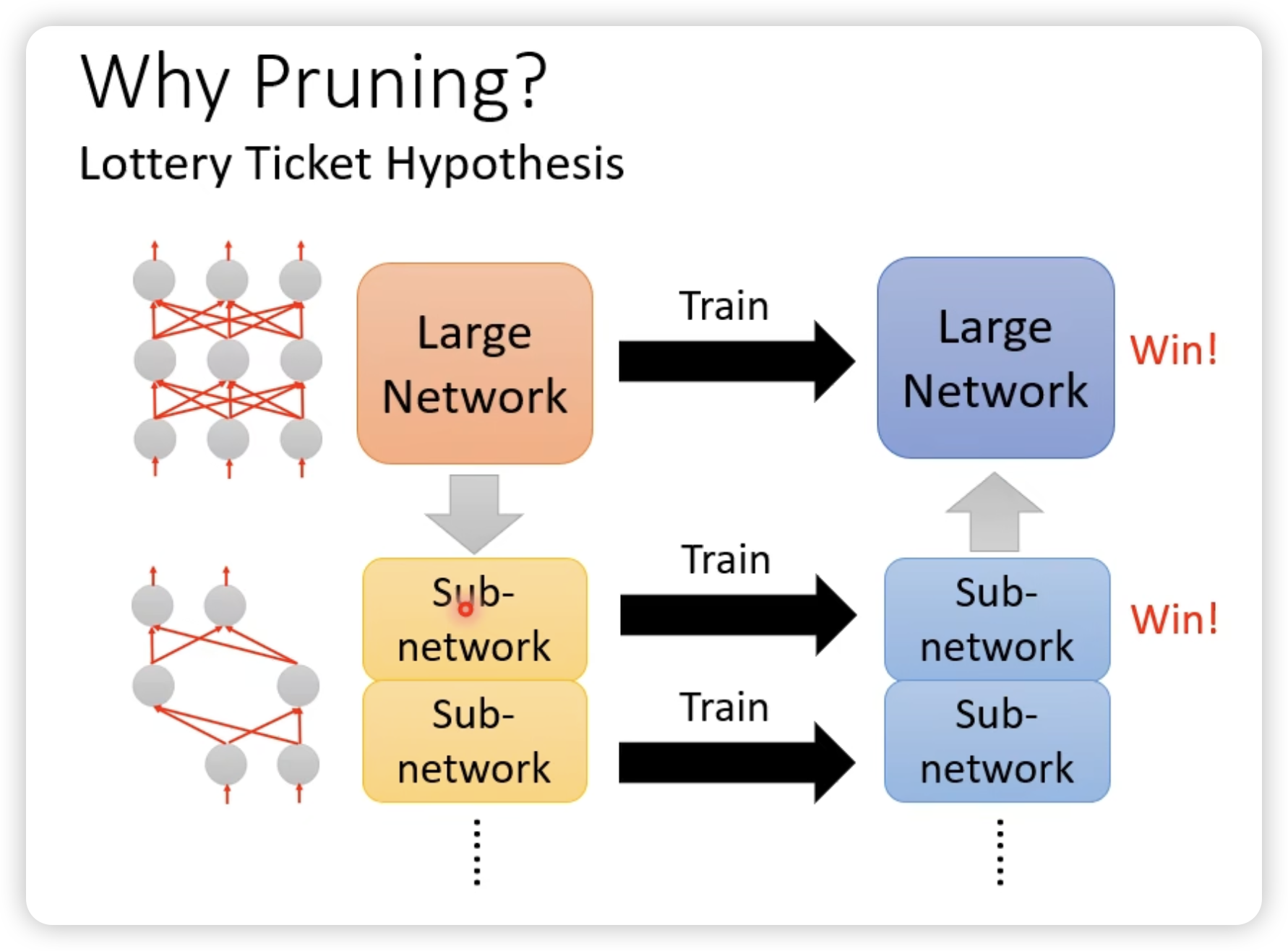
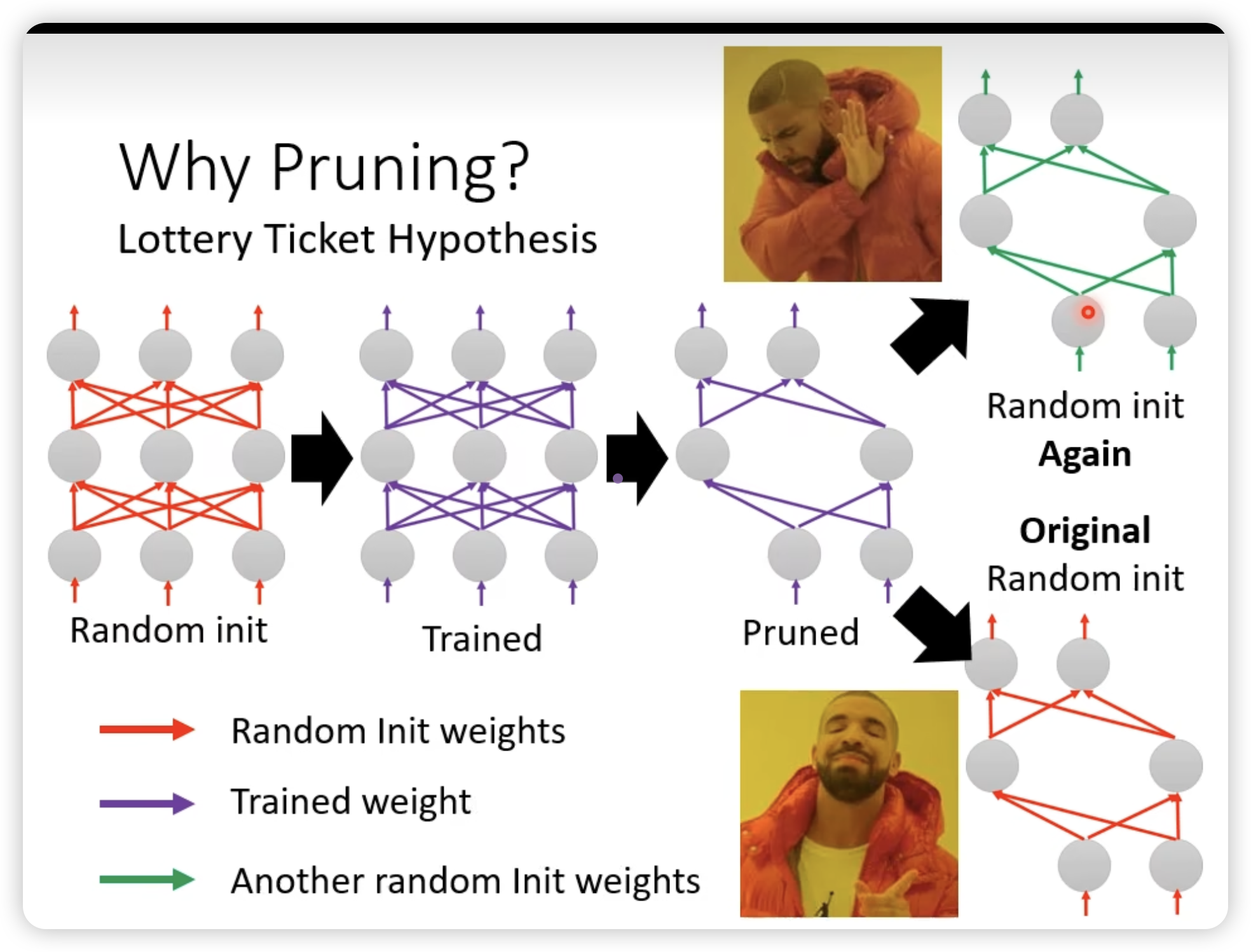
一个很有意思的发现:
大模型里面小模型中奖了可以出结果,所以从大模型pruning出来的小模型是幸运的可以train的起来的参数。(与之对比,重新初始化结构相同的pruning出来的小模型是不行的)
Knowledge Distillation
为什么不直接train一个小的network?因为效果不好。
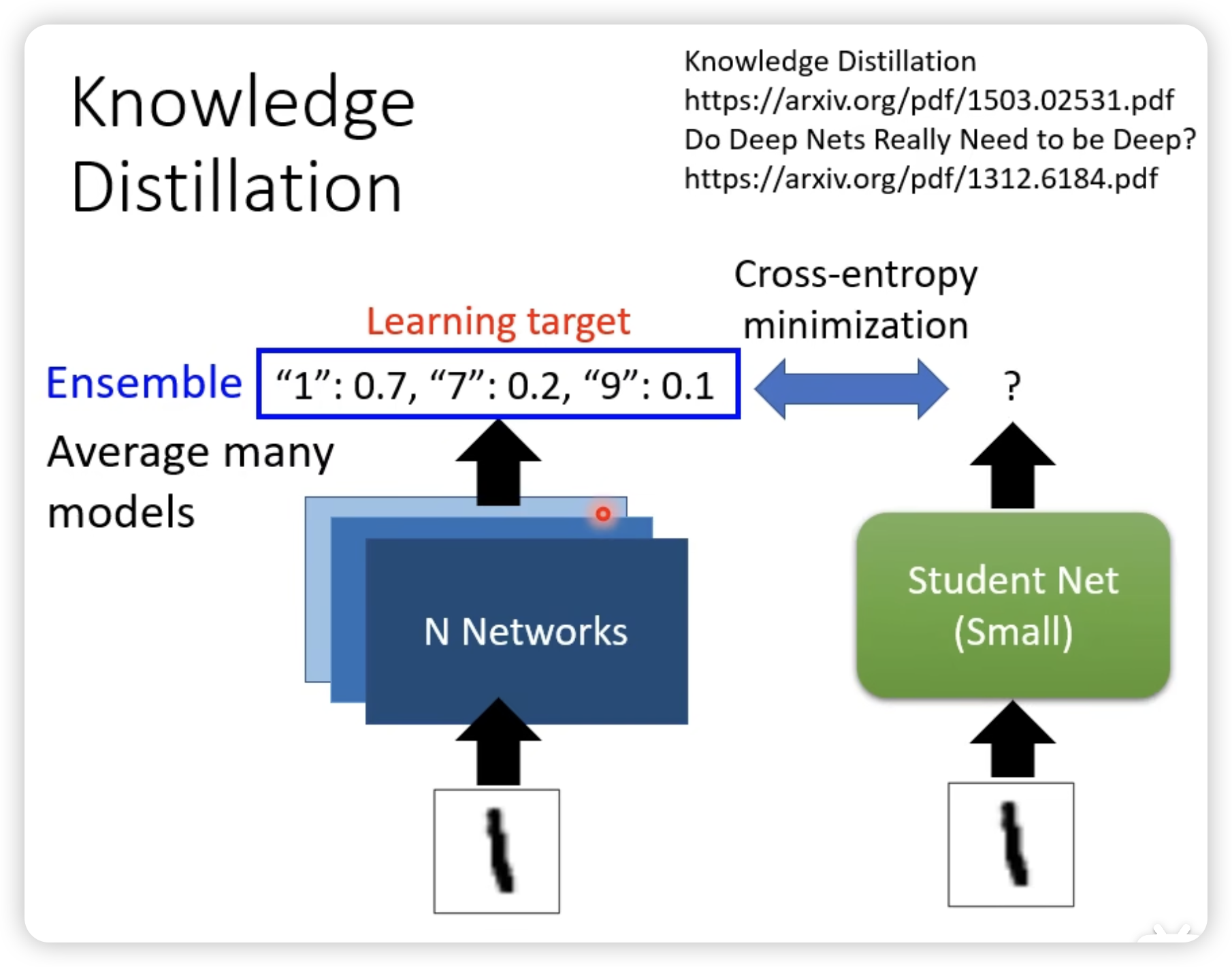
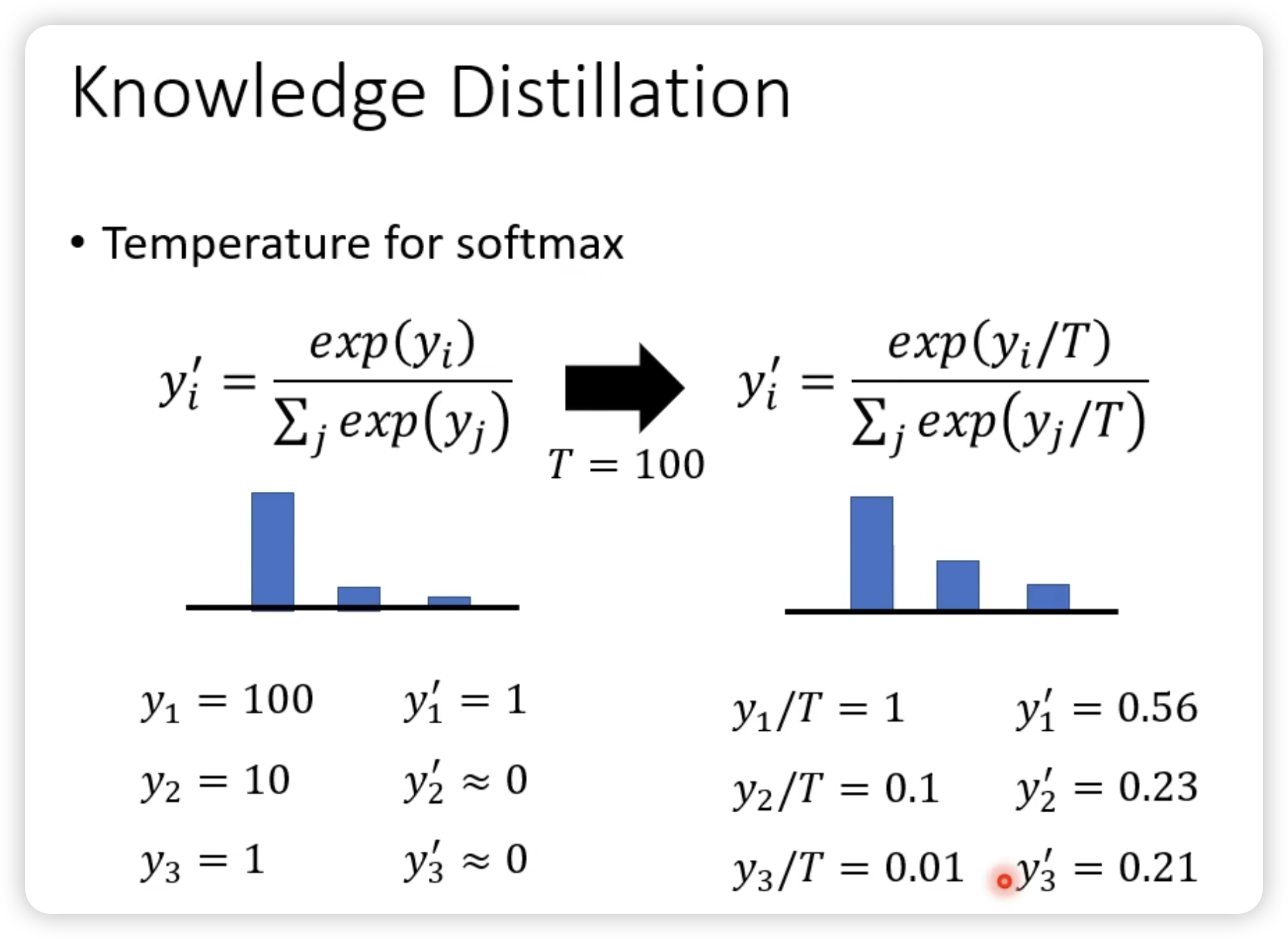
一个直觉的说法,是teacher可以提供额外的咨询。
比如老师告诉说,1和7比较接近,而不是0%,100%。(比较平滑?)
同时注意到,knowledge distillation在model ensemble上的运用,实际中很难同时做1000个模型output的ensemble,但是我们可以提前train的一个对于ensemble结果的蒸馏模型。
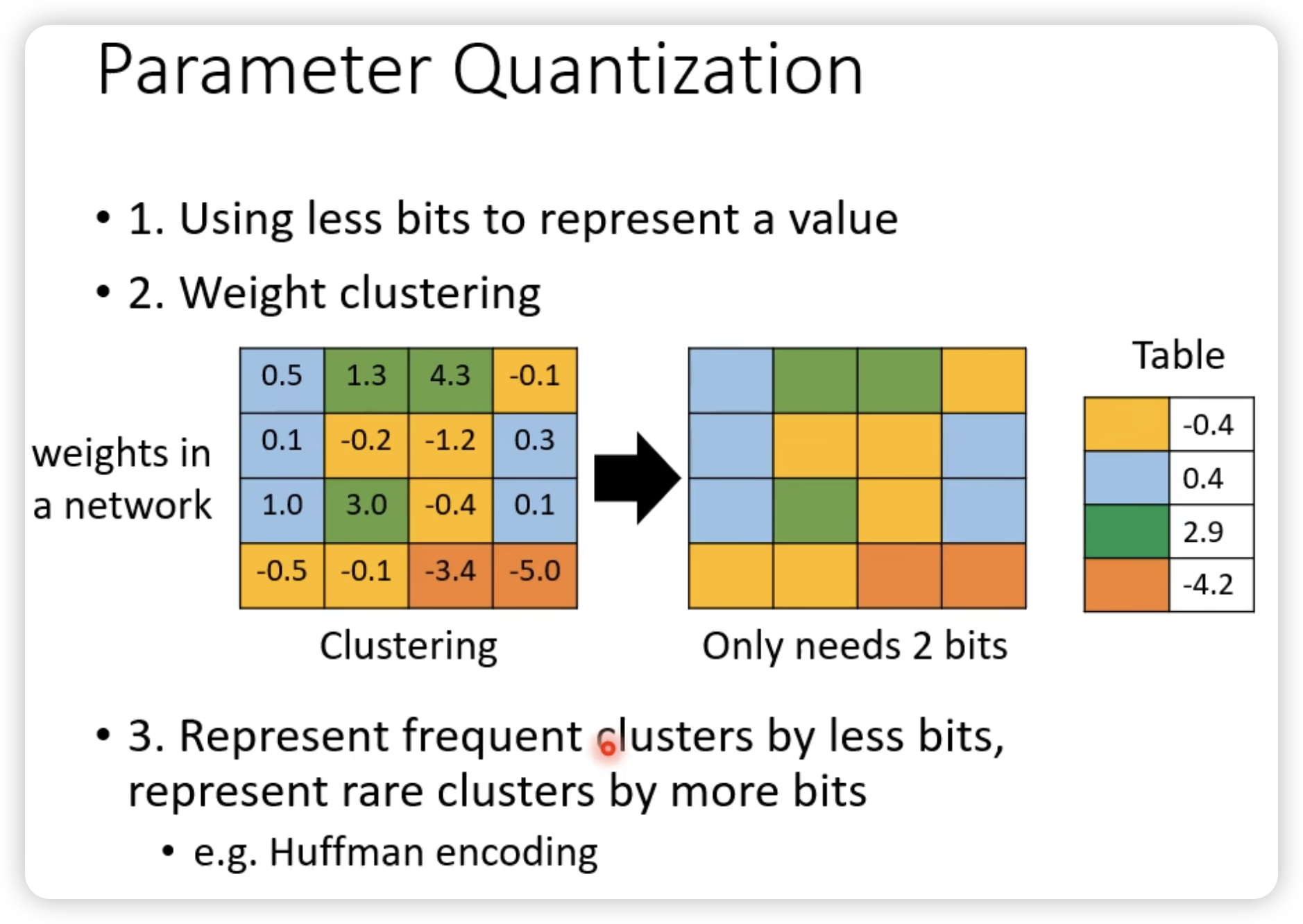
Parameter Quantization
用一个小点的bit来表示参数。
- Binary Neural Network

一个参数值要么是1,要么是-1。
Architecture Design
这是传统的CNN:
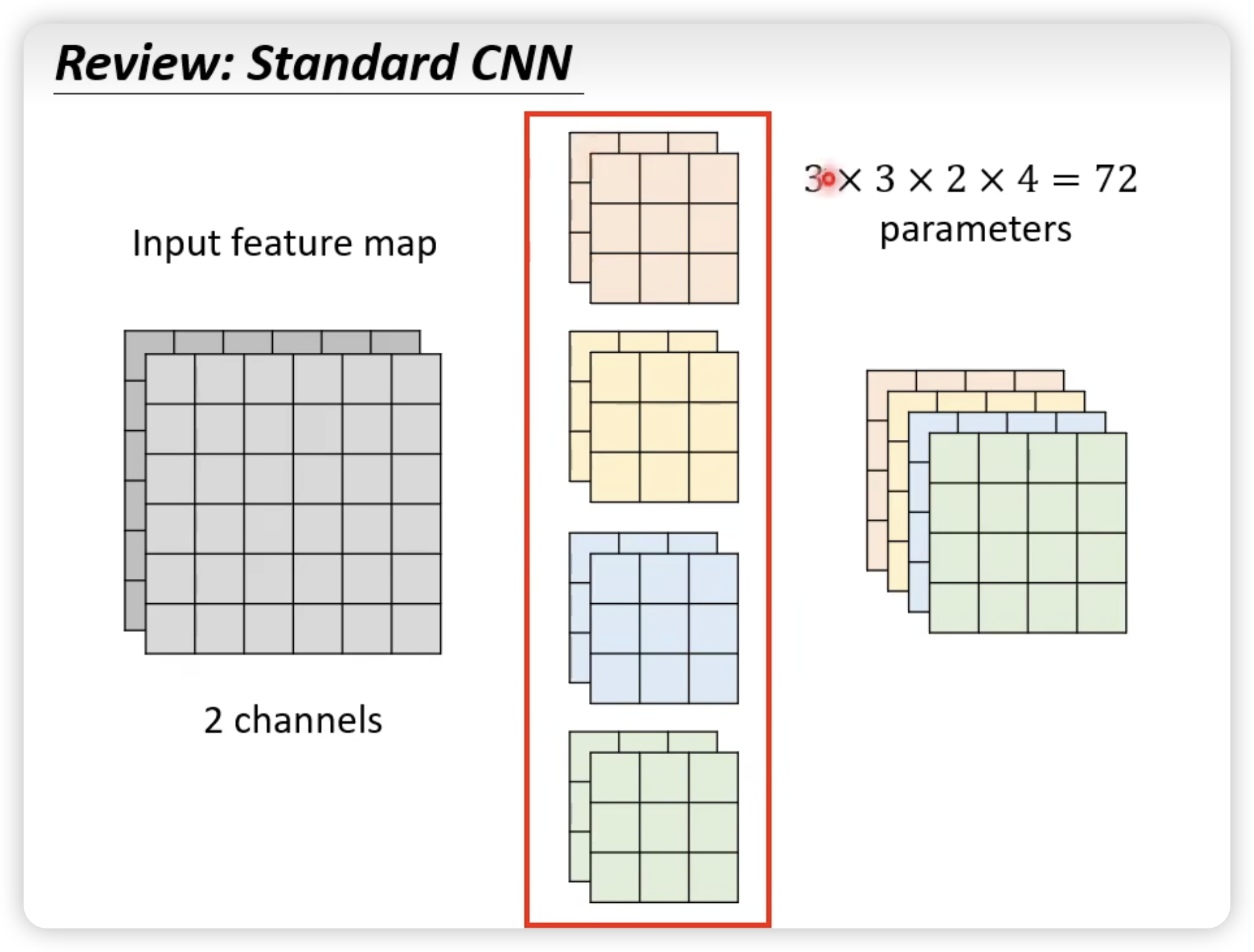
这是改后的Depthwise Separable Convolution:
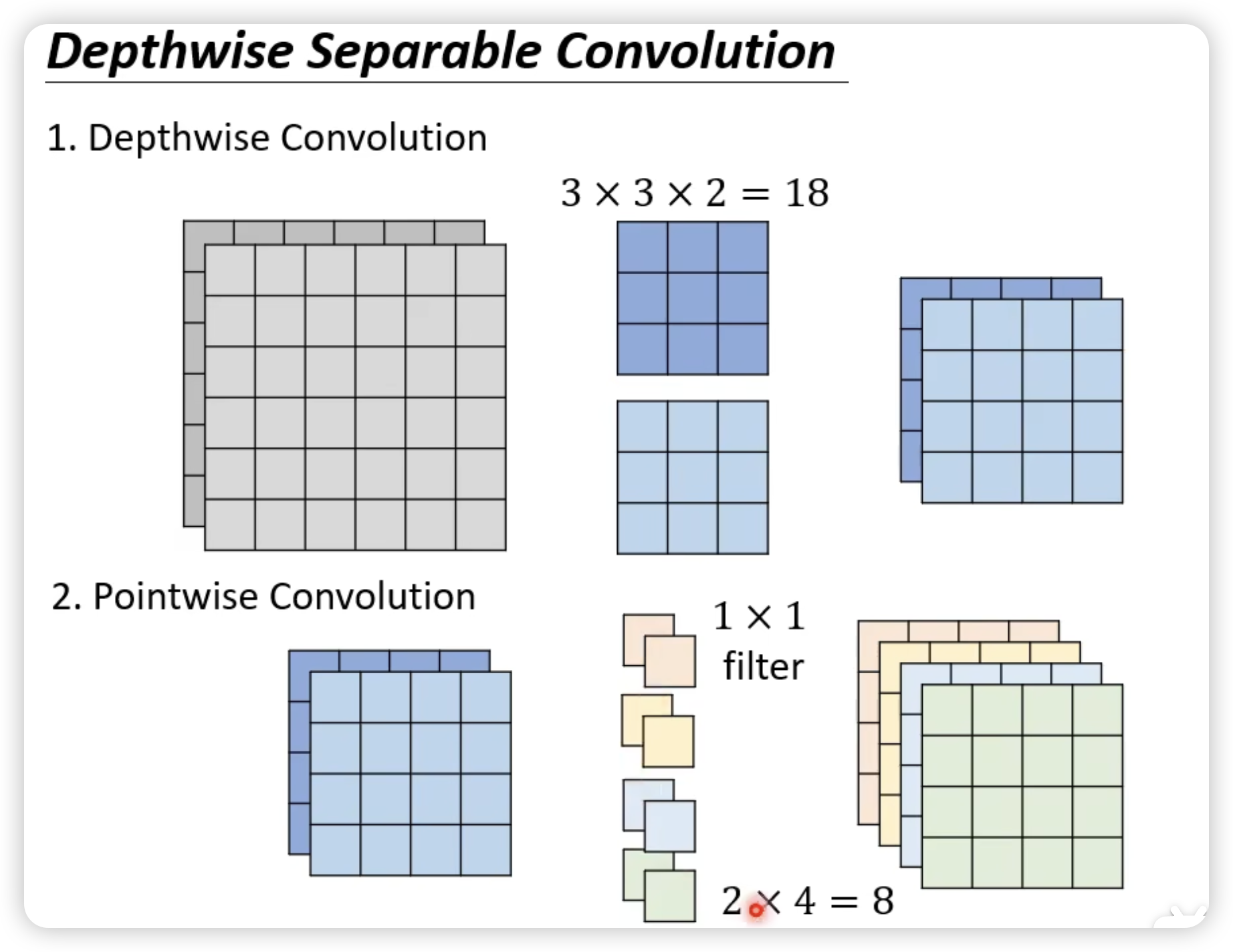
比较:
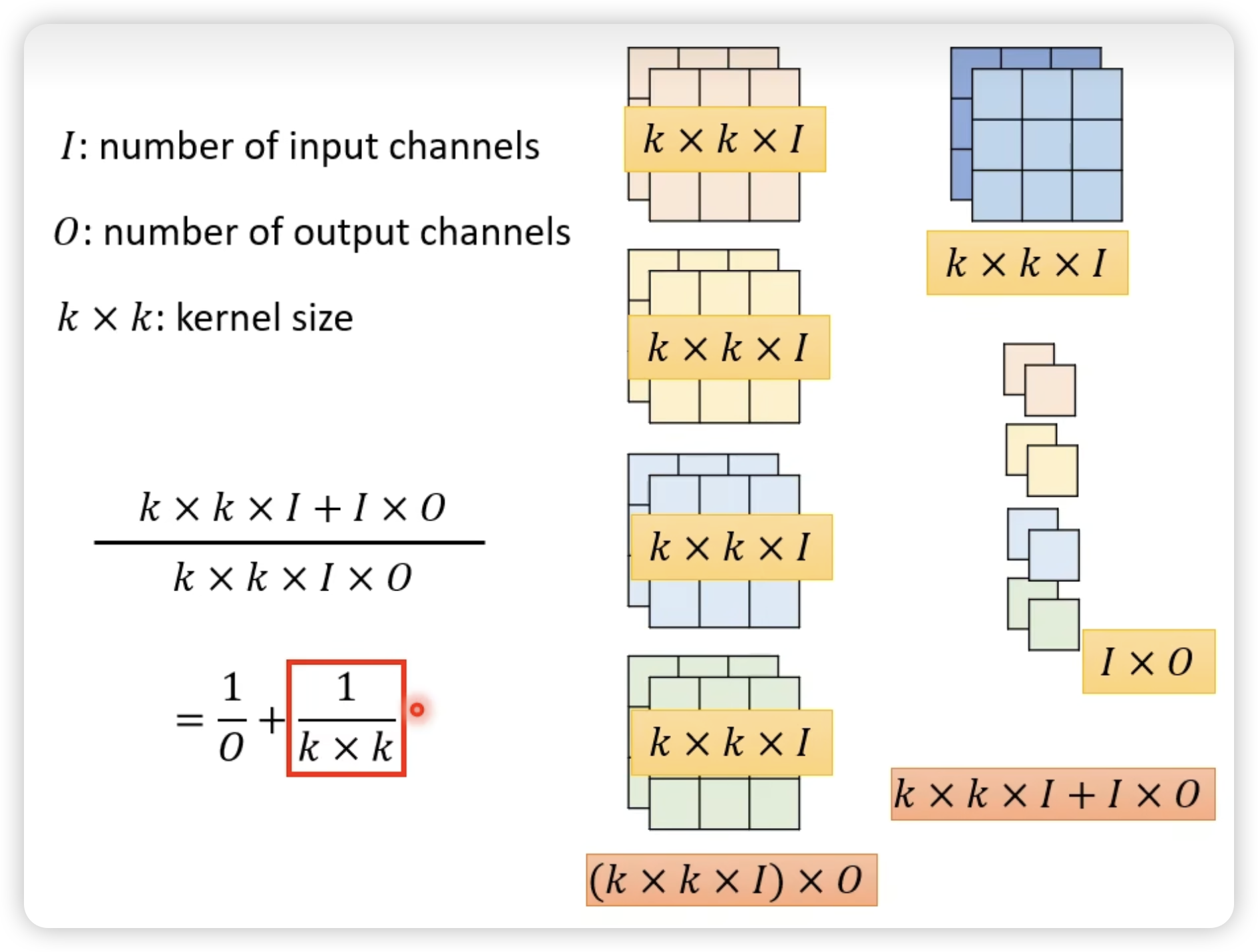
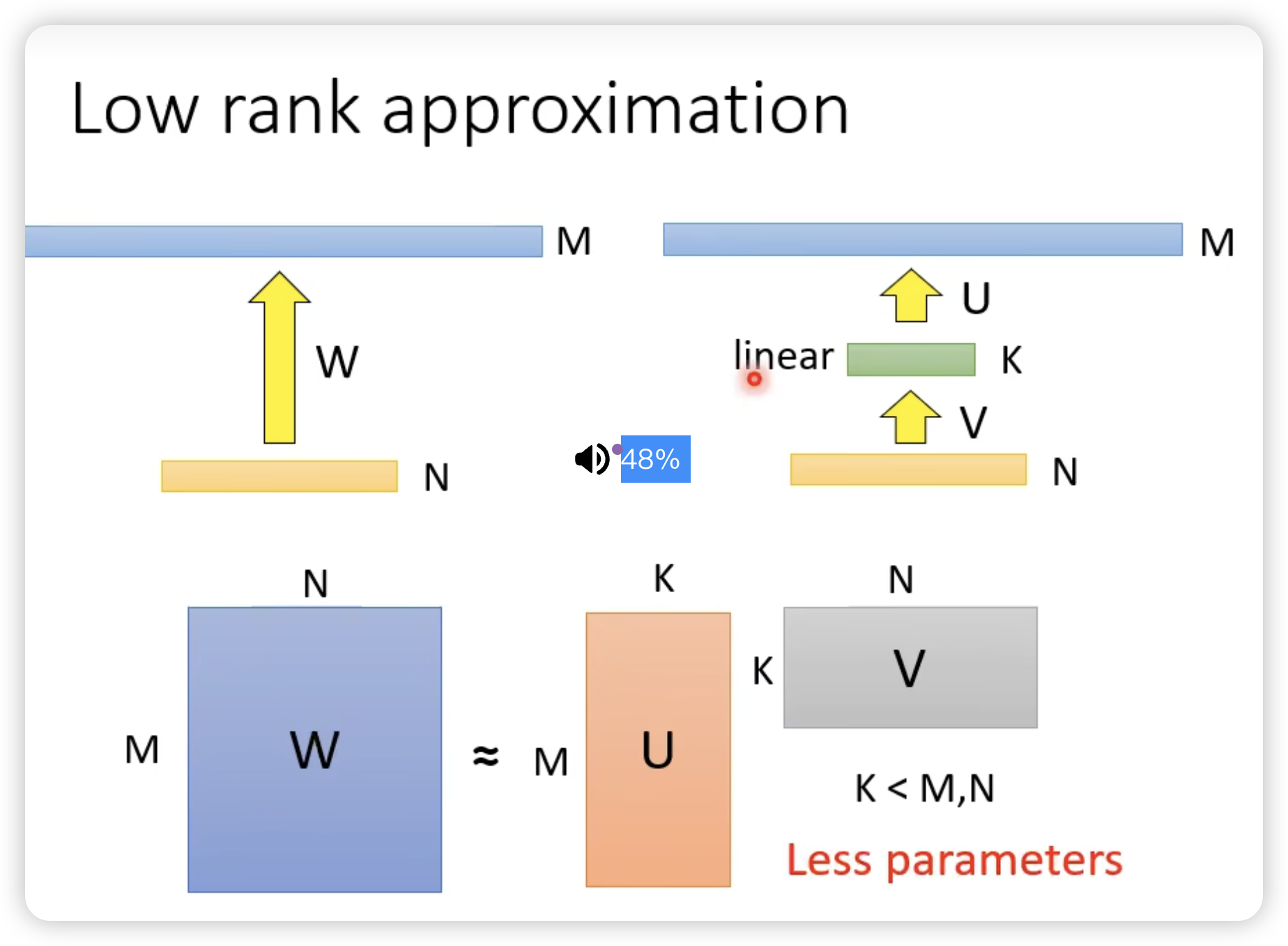
原理:
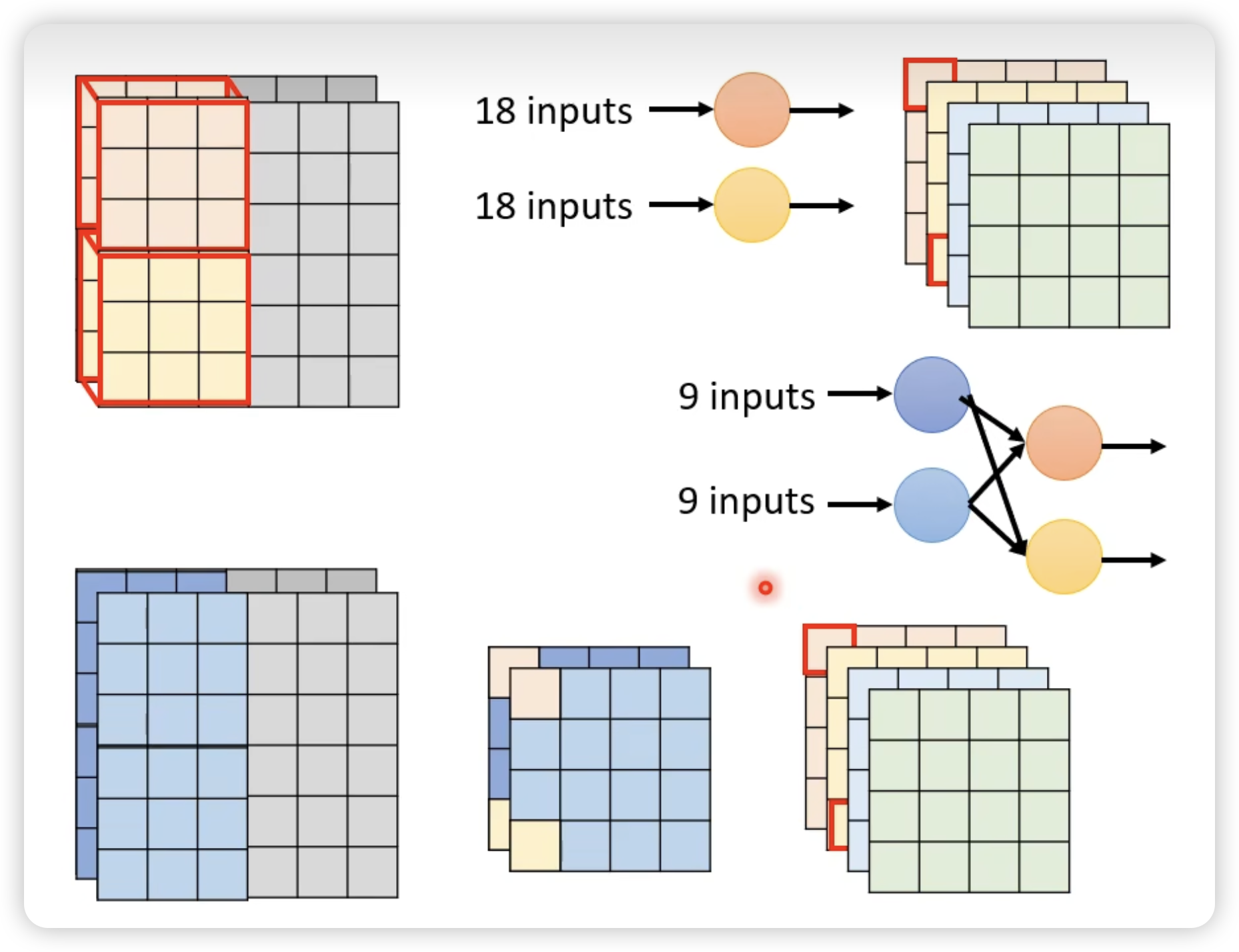
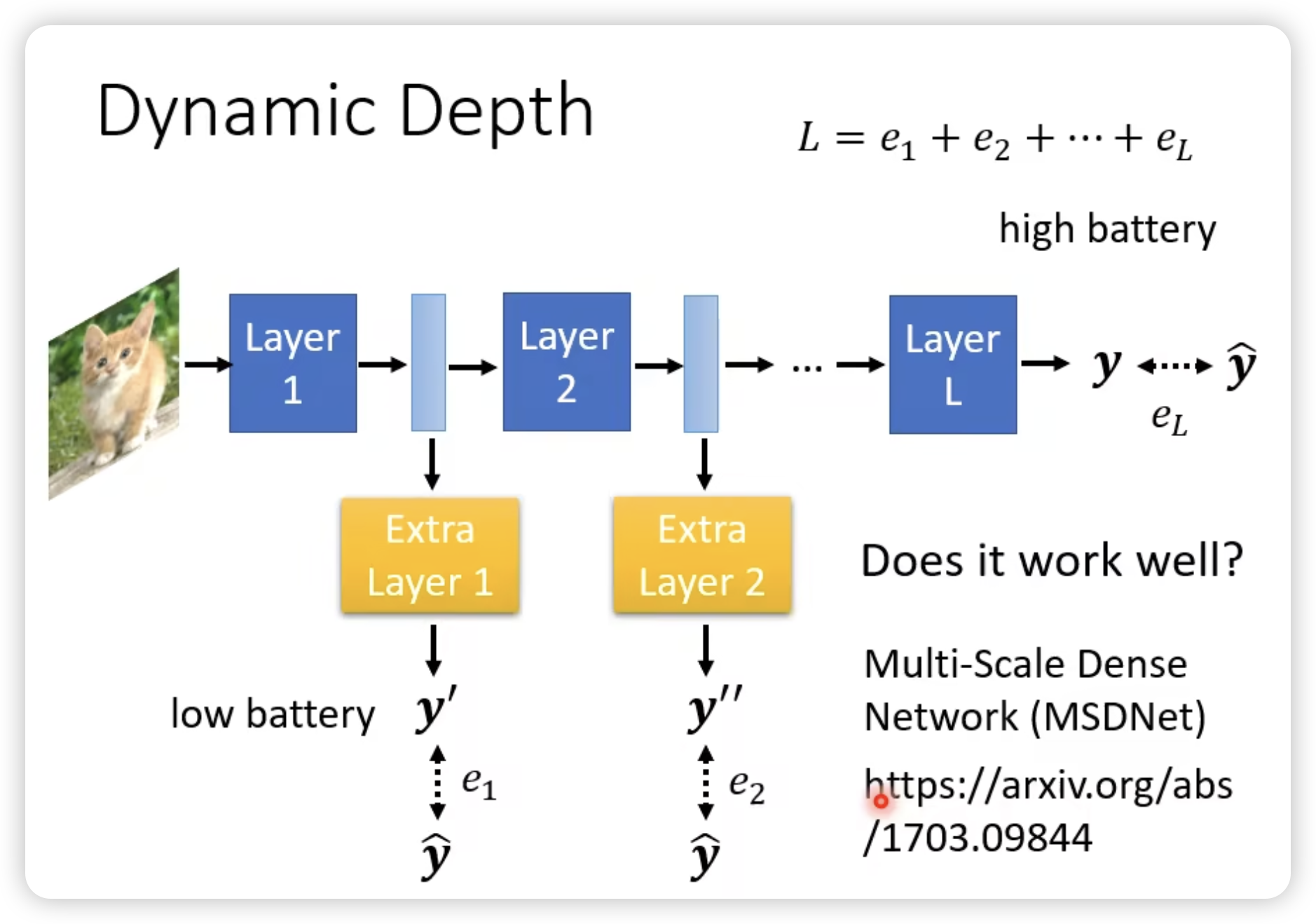
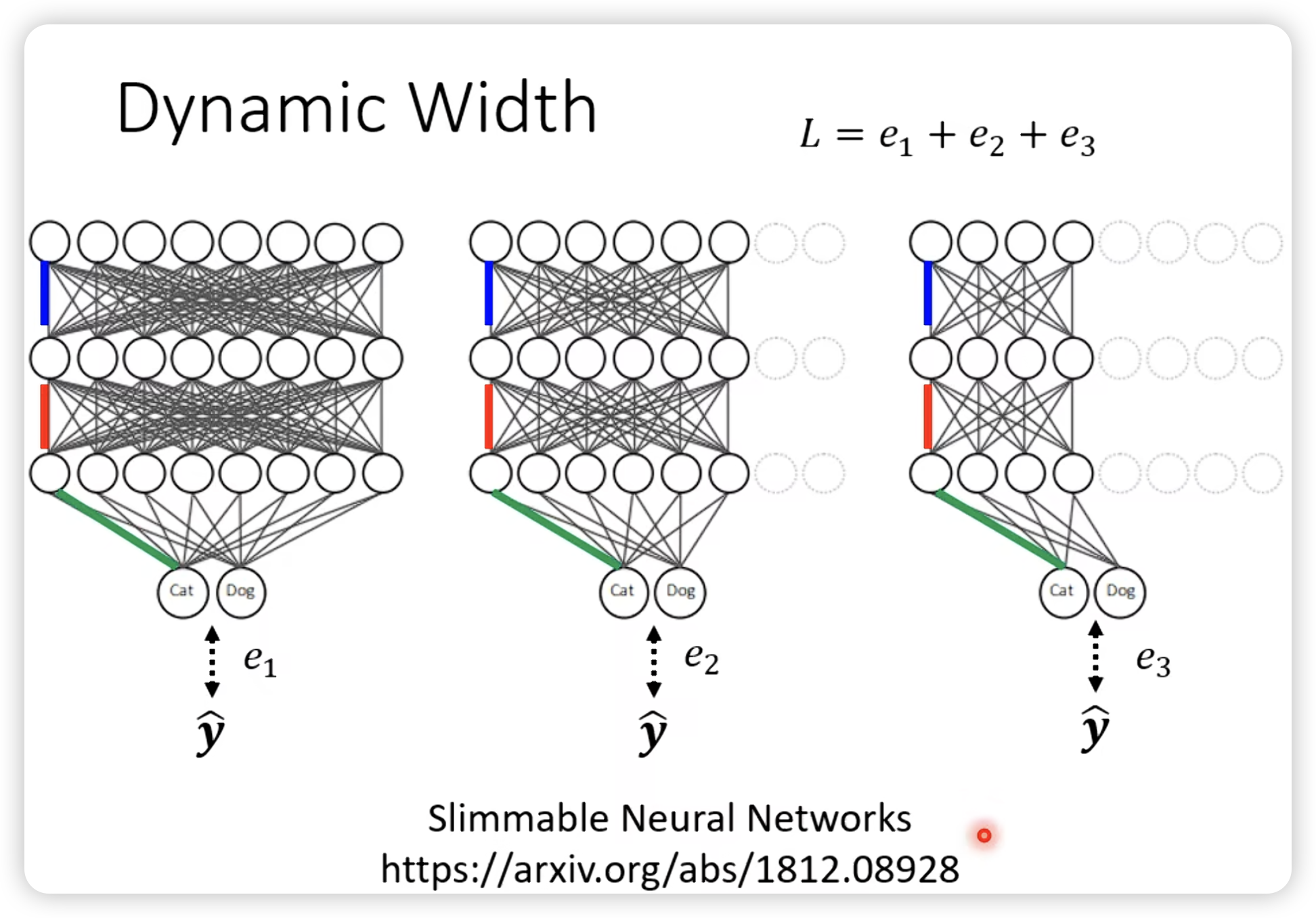
Dynamic Computation
让network自由地调整自己的计算量。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.