
SVM
Support Vector Machine (SVM)

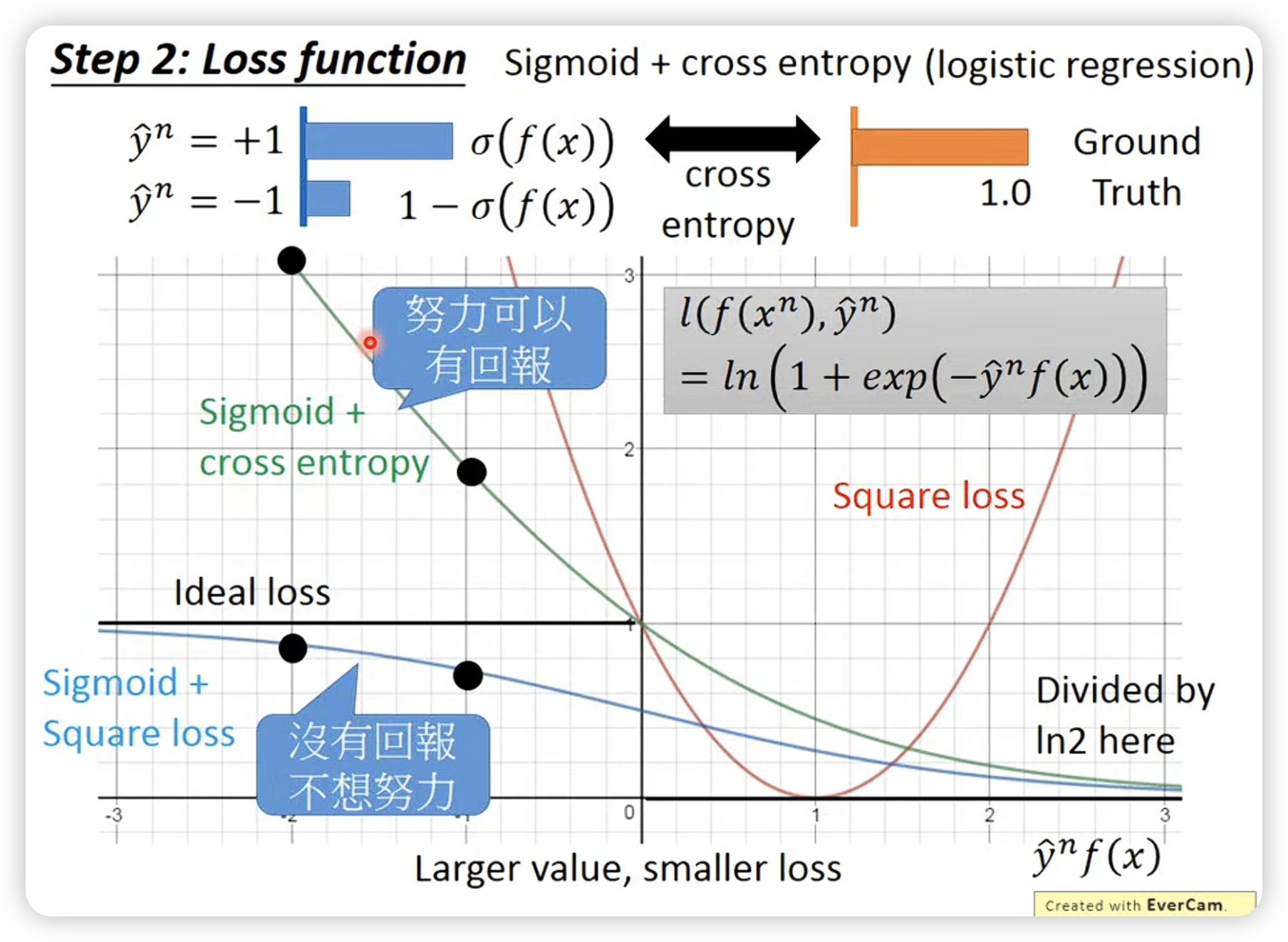
- hinge loss function:
max操作促使f(x)大于1,且不需要超过1太多,对比cross entropy: hinge loss及格就好:
(也是ideal function的upper bound)
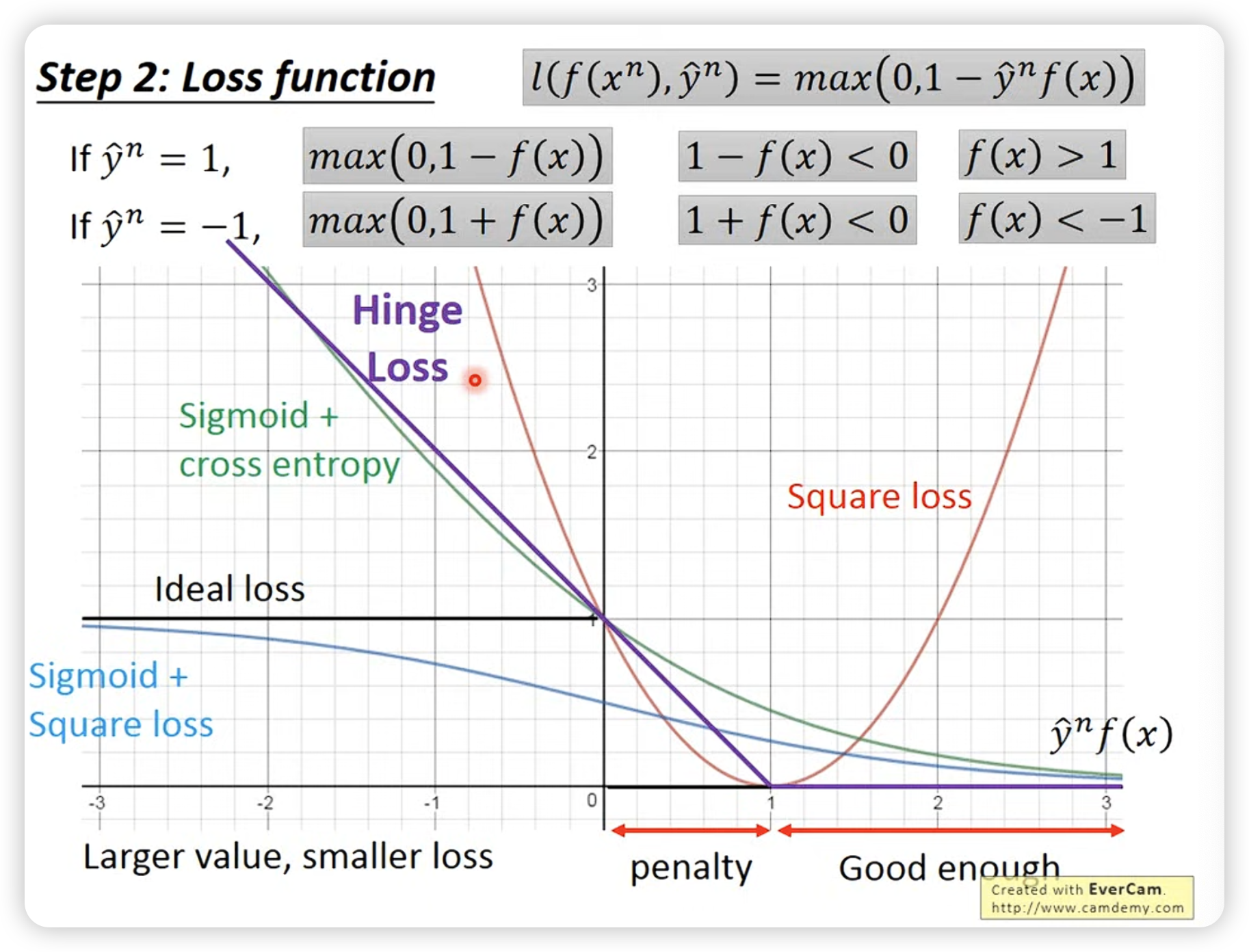
SVM和logistic regression的区别就是定义的loss function不同,SVM的loss function是hinge loss function,logistic regression的loss function是cross entropy loss function。

脑洞一下,linear SVM可以用gradient descent来求解。

常见的做法:

- SVM特点
- w参数实际是x的线性组合,所以SVM是线性分类器。这一点可以用lagrange multiplier或者梯度下降来证明。
- 是sparse的,大部分是0,也就是说SVM结果只和少数几个样本有关。

经过等价变化,和最后一步推广,产生kernel trick。
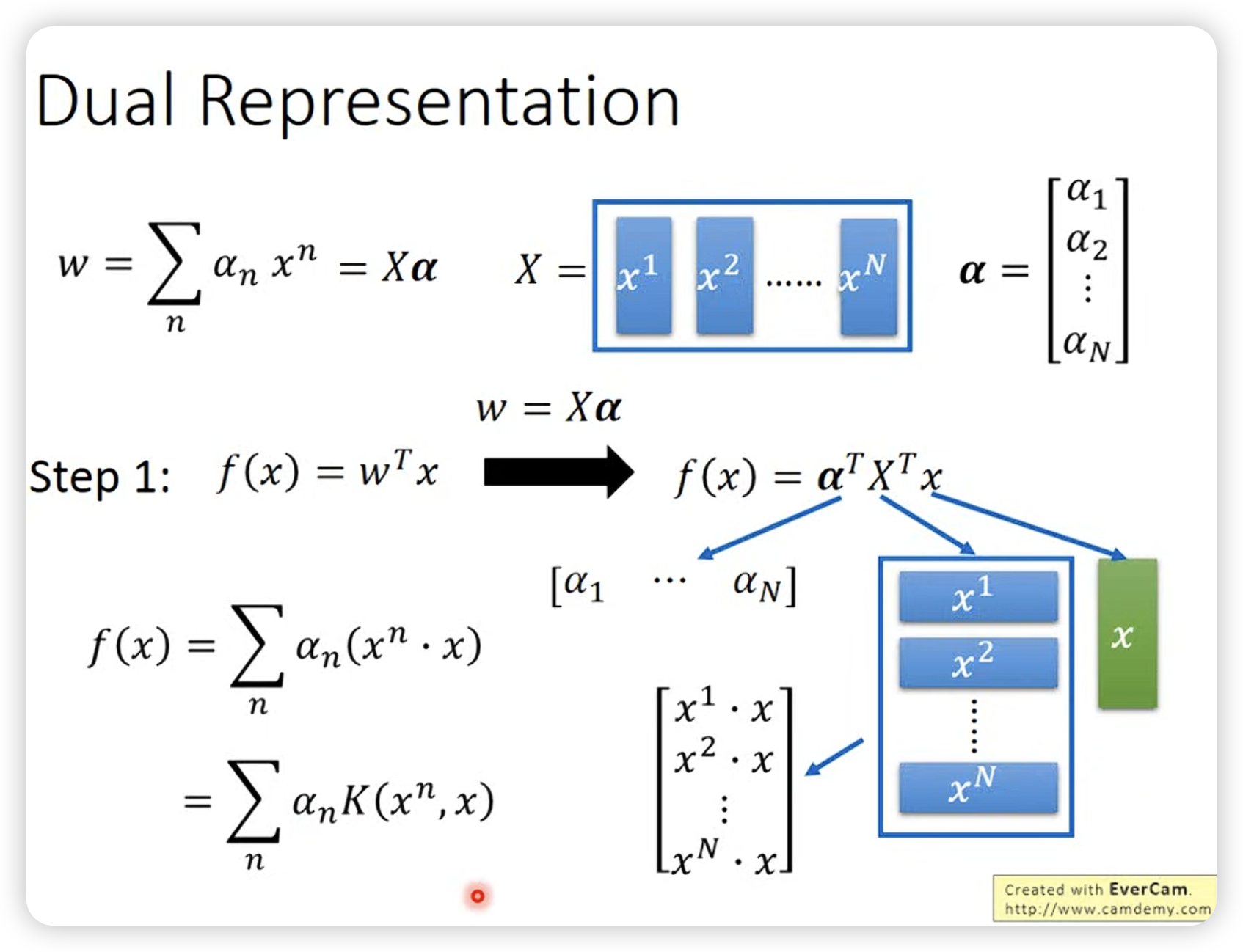




当使用RBF kernel,如果不使用kernel而是朴素的特征变换,需要的特征维度是无穷的,而kernel trick可以避免这个问题。
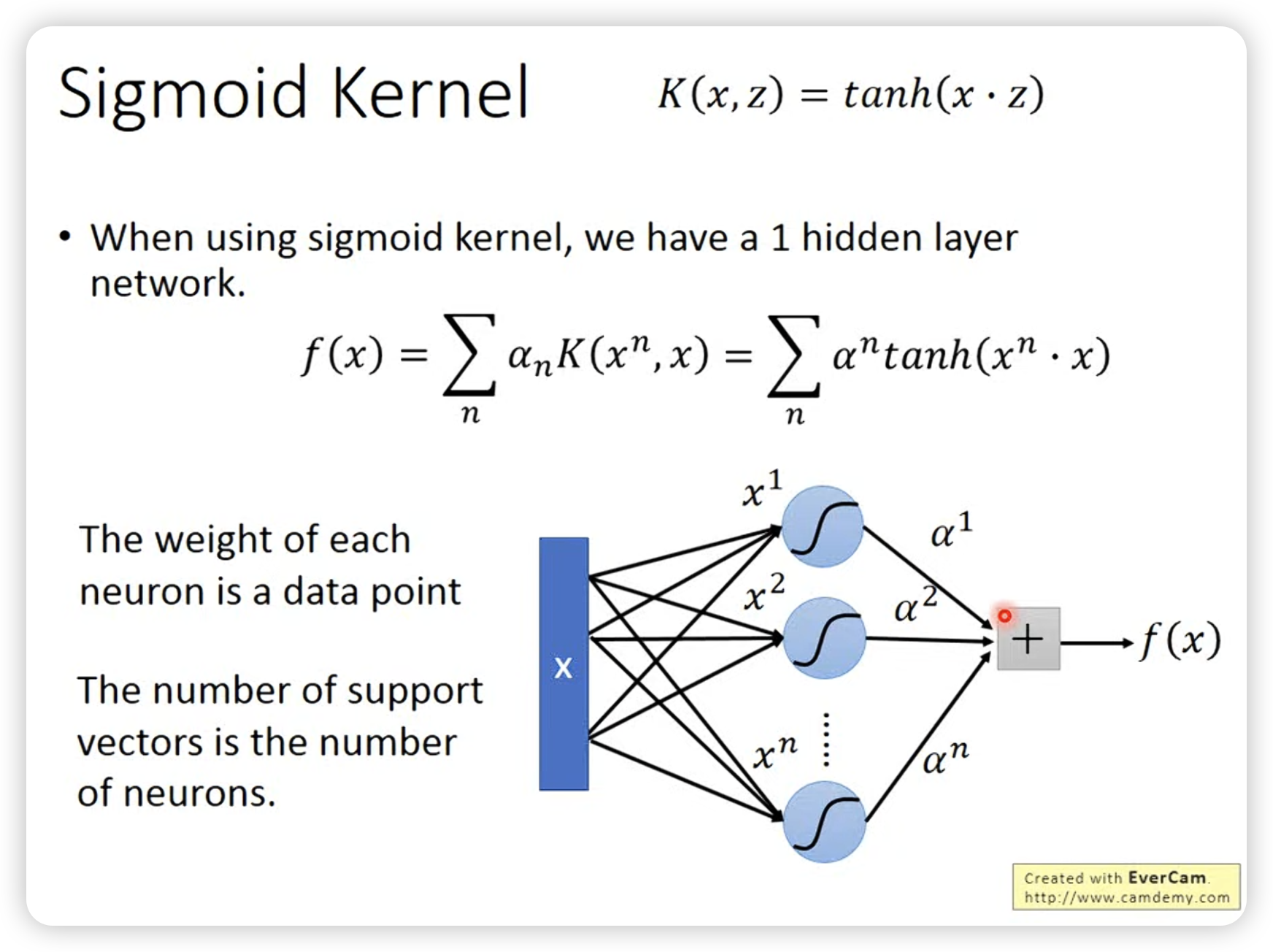
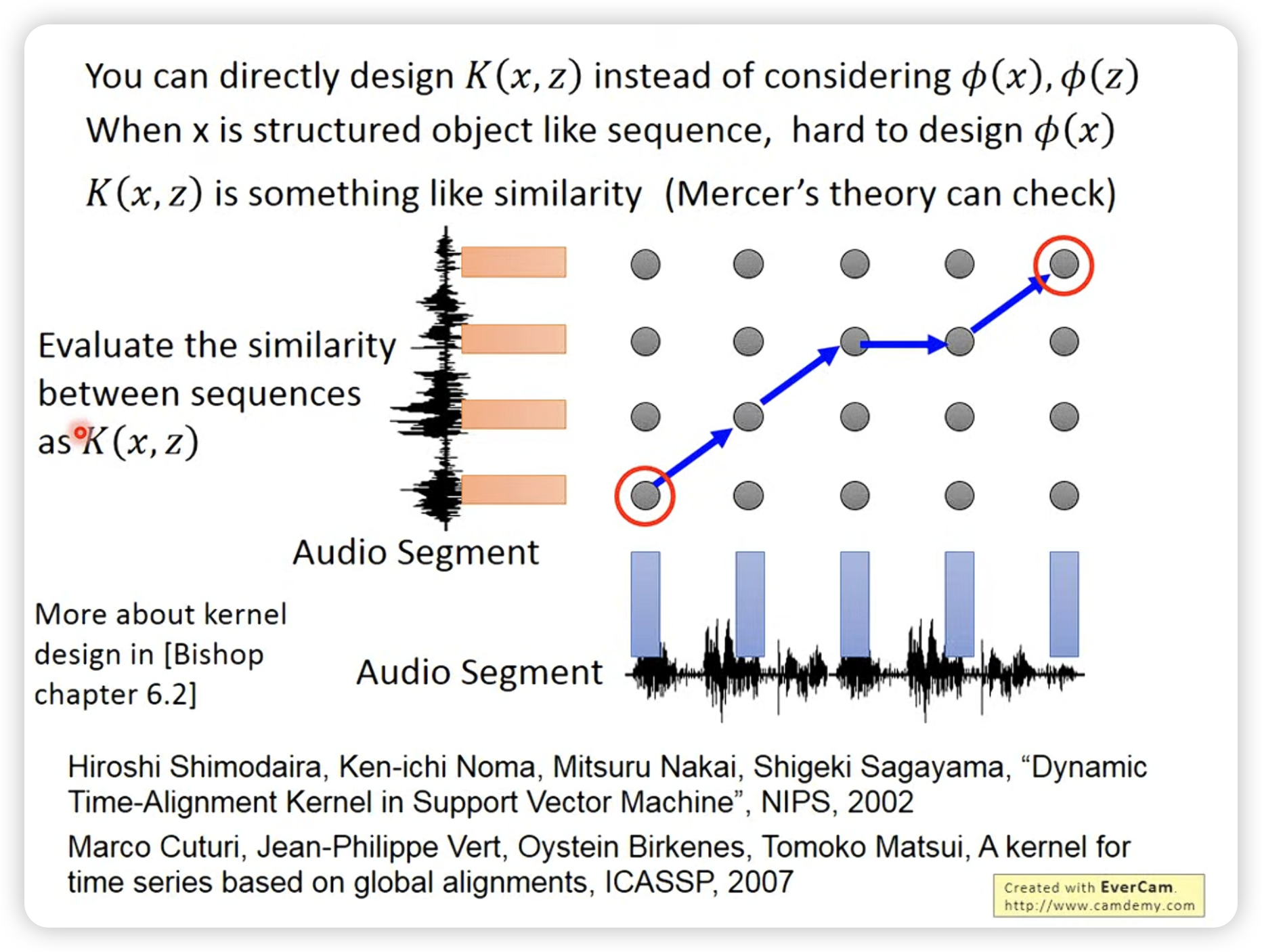
Kernel function是一个投影到高维的inner product,所以往往就是something like similarity
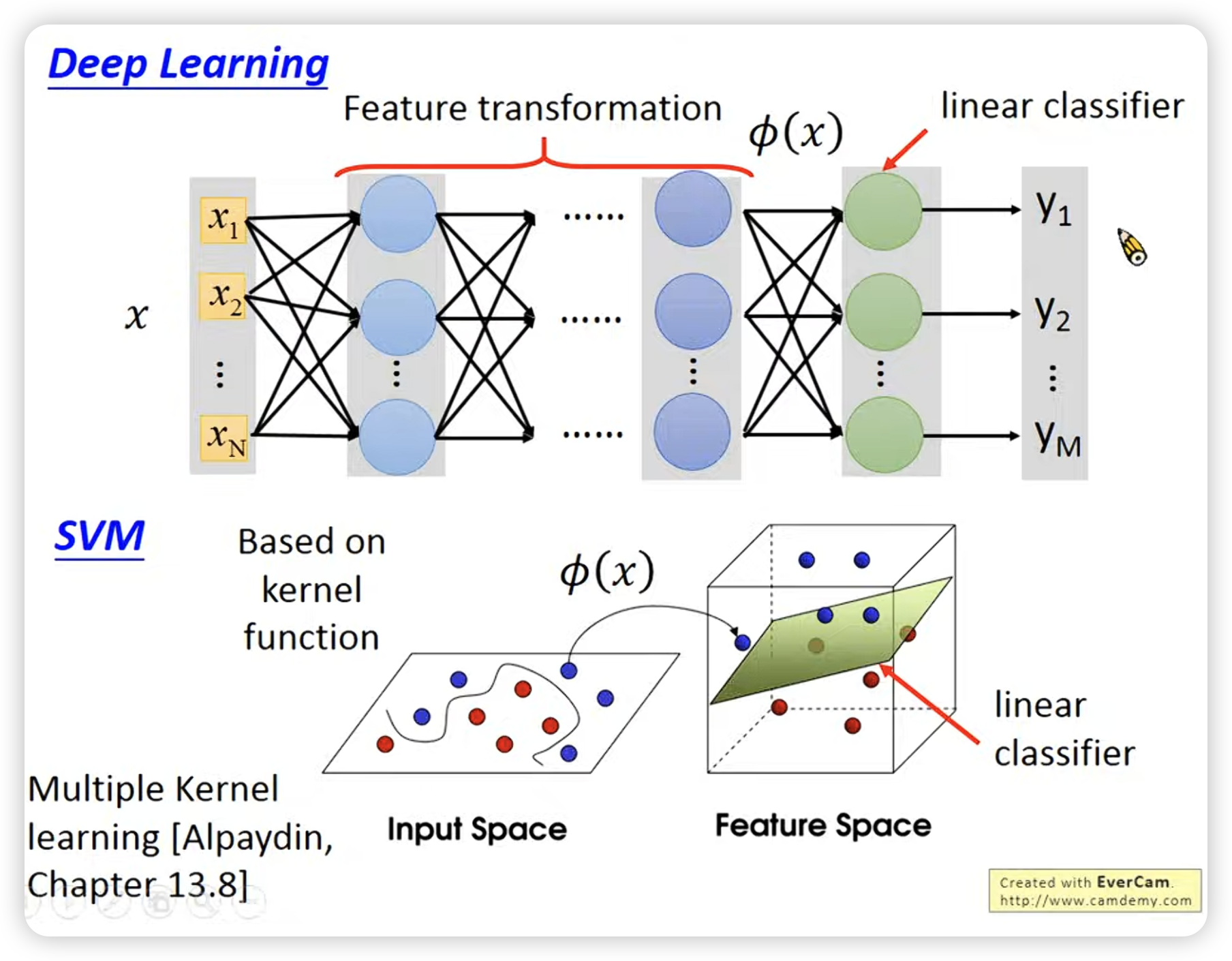
与deep learning的比较:
这个很形象也很重要:
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.