
Accelerating Techniques for self-Attention
Accelerating Techniques for self-Attention
detect0530@gamil.com
计算量和耗时
当输入序列很长时,在key和query计算dot-product时候计算量非常的大。(瓶颈)
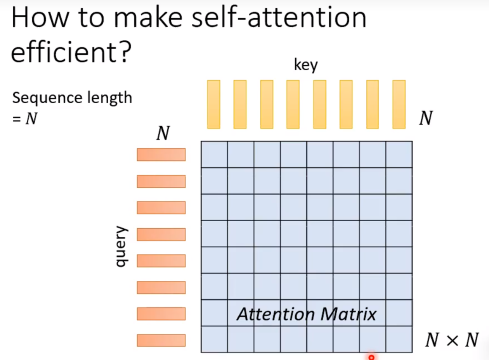
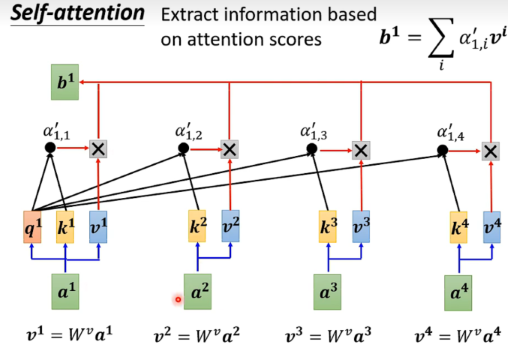
当input的sequence数量很大时,transformer模型中self-attention组件是最耗时的,也就是运算量的瓶颈,那么如果我们加快self-attention的运算速度,就可以加快整个模型的训练速度。
加快 Self-Attention运算的方法
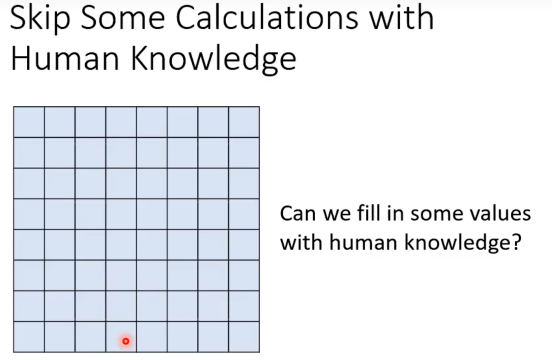
Skip some calculation with human knowledge
也许不需要把attention matrix所有值都算出来。
Local Attention
举个例子,如果只有sequence相邻的部分才有作用:
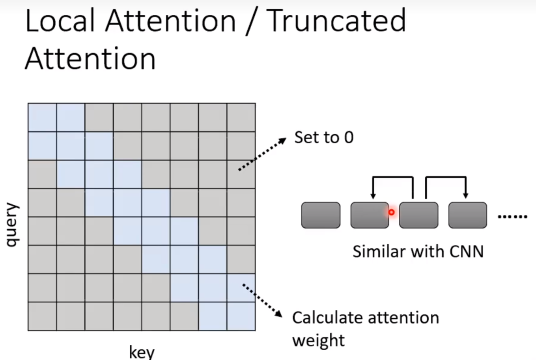
相当于每次做attention只看一个小范围的区域。但是这样做的话,和CNN就没什么区别了,也就是说虽然这样可以提速,但是效果不一定会很出色。
Stride Attention
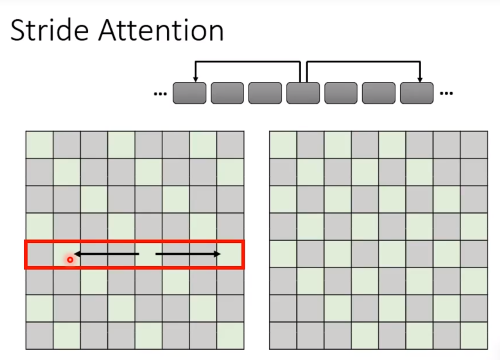
同时也可以隔固定x位置看一下。
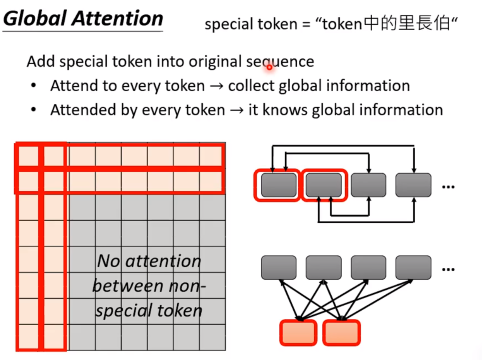
Global Attention
选取或者新增一些special token,作为中介,所有token与special token互相联系,此时,信息的传递都通过special token实现。
那么这么多选择,怎么办呢?
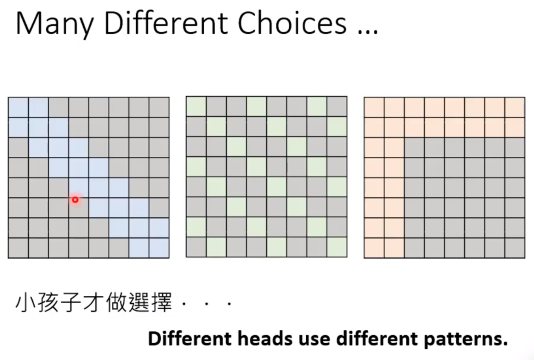
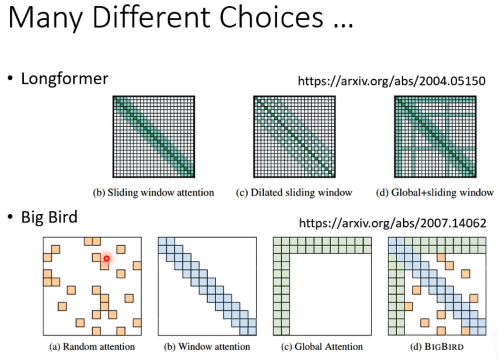
答案时全都要,既然不知道哪一个更好,那么在self-attention的时候使用多头机制全用上就好了。
一些进阶的例子:
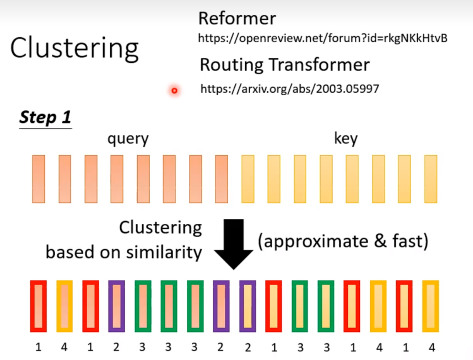
Clustering
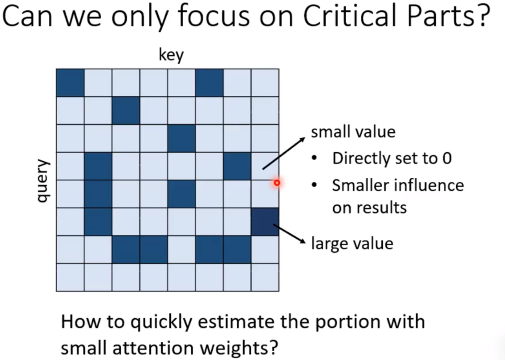
如果我们能估计一些占比很小的attention weight,那实际上可以直接set to 0。
按照相近的query和key的vector属于同一个cluster
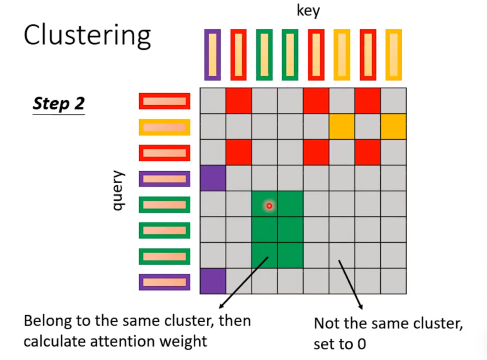
只有在同一个cluster的token之间才会算attention,其他的attention weight都设为0。
以上的做法要计算哪些attention位置都是基于人类对问题的理解。
Learnable Patterrns
学习另外一个nn,输入input序列,每一个元素都通过nn输出一个vector,然后这些vector组成一个矩阵,这个矩阵就是选择的attention matrix标准。
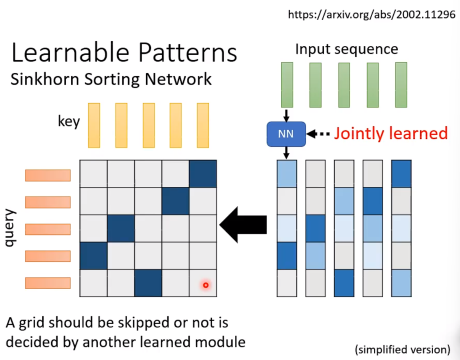
低秩法
往往attention matrix是低秩的。
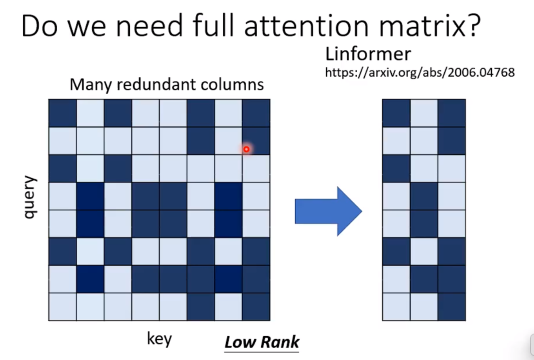
选择最具代表性的K个key(降低秩),只用计算这K个key和query的dot-product。
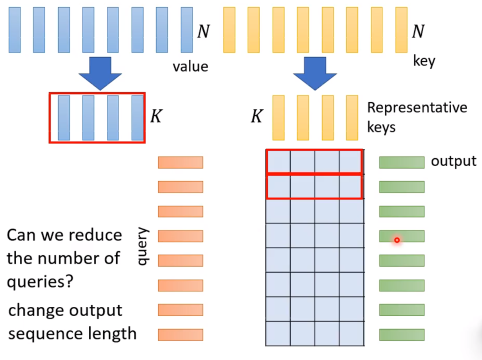
我们选择了K个key vector,然后出了n*k的attention矩阵,那么接下来需要用value vector和attention matrix做一个求和,所以还需要对value的向量组做同样的压缩,提取K个最优代表性的value vector。
看到这里,或许会想,为什么不把query也压缩一下,这样就可以减少计算量了。但是为了保证输出的sequence长度不变,query的个数是不能变的。(当然,输出长度在一些问题如情感二分类问题下是可以变的,需要具体问题具体分析)
接下来如何选择有代表性的K个key vector呢?
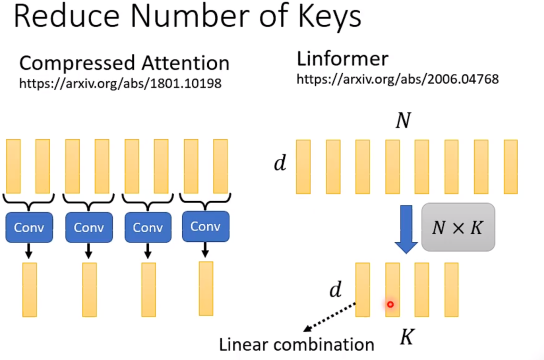
- 利用卷积
- 乘上一个N*K的举证,相当于对于原向量组做K个线性变换,我们认为这样的线性变化提取的K的向量是有代表性的。
加速矩阵运算
回顾:
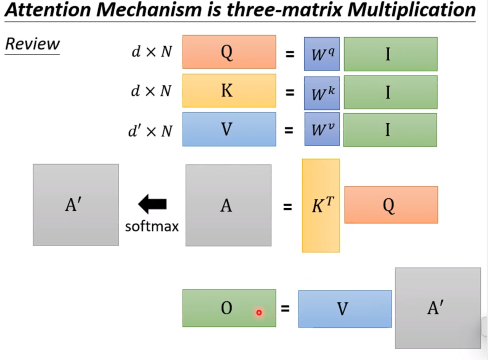
我们希望加速这一块的运算。
首先假设不看softmax,我们发现:
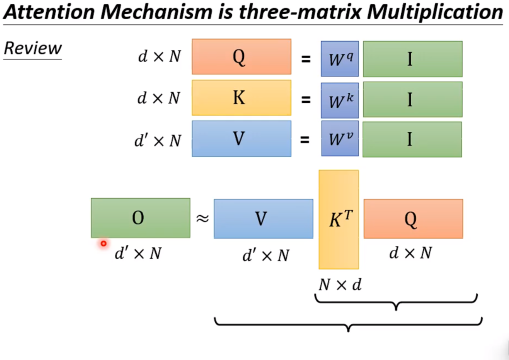
其实通过矩阵乘法的结合律,我们可以把这个运算变成:
现在我们放回softmax部分:
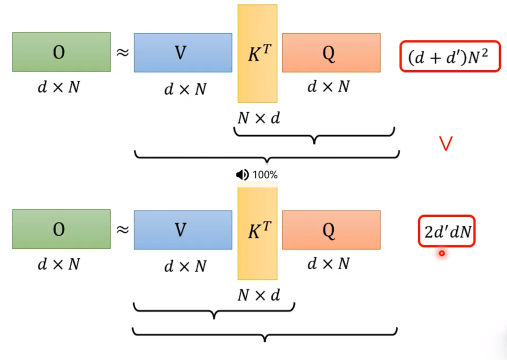
首先,我们回顾是怎么算的:
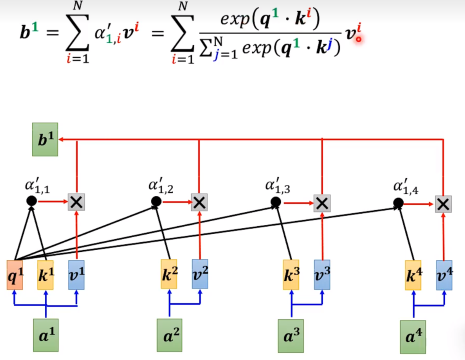
接下来,我们通过构造,并做变换:
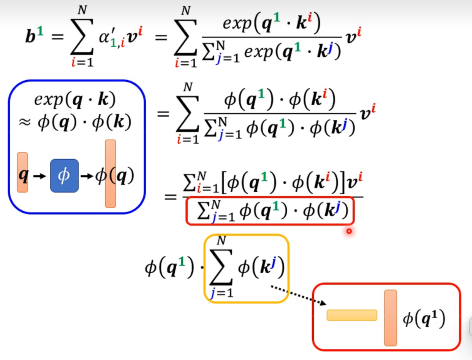

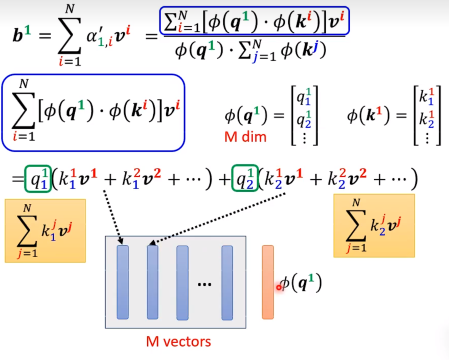
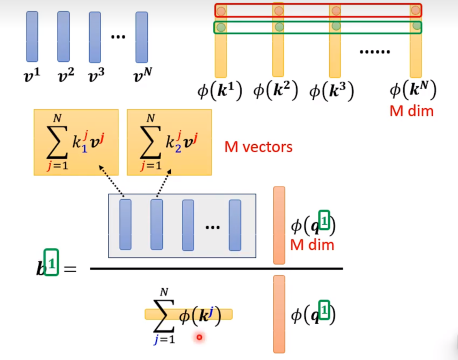
通过预处理算出公共的矩阵,算可以很快的计算。每次就只用算红色的M维向量再乘一下算好的矩阵就可以了。
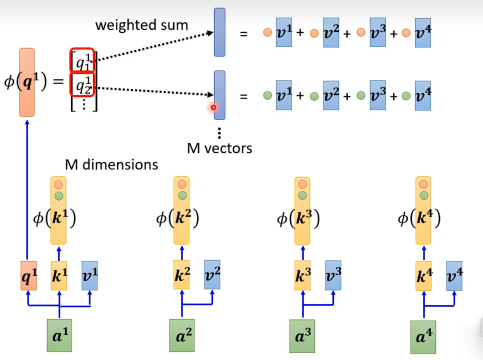
接下俩关于函数的设计,就是不同论文有不同的方法了。
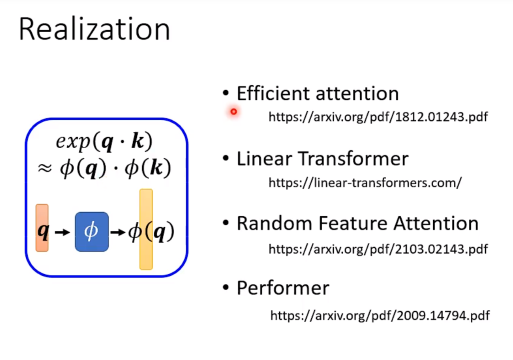
Attention 一定要用key和query做dot-product吗
实际上,Attention matrix可以直接设置为固定的参数,这些参数加入网络里面去学习。
可能会说,input不同的序列,attention matrix不都一样吗?确实,但是表现不会变差。所以重新让我们思考attention的价值到底是什么。
Summary
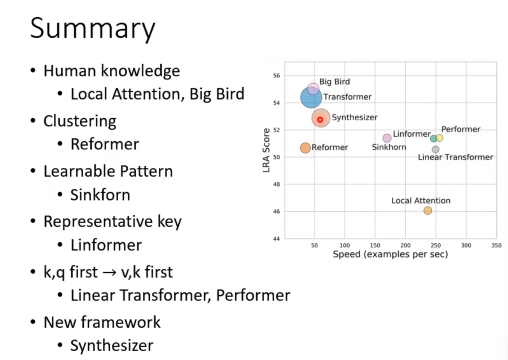
- Big Bird 人为去设计需要关注哪些位置,Big Bird是组合了很多方法的。
- Reformer用聚类的方法,去确定attention哪些位置(同一个聚类)。
- Synthesizer 完全用Attention Matrix当成network的参数去训练。
- Sinkforn 直接用network来决定哪些位置需要关注。
- Linformer 选择一些代表性的key向量和value向量(直接降低矩阵大小)。
- Linear Transformer 用低秩法,降低attention matrix的秩。