for i inrange(args.size): idx, idy = np.random.choice(args.size, 2) x, y = old_group[idx][0], old_group[idy][0] x, y = Two_point_crossover(x, y, args.prob_c) x = Bit_wise_mutation(x, args.prob_m, graph, n_edge,old_group[idx][1]) y = Bit_wise_mutation(y, args.prob_m, graph, n_edge,old_group[idy][1]) fitness_x = Get_fitness(graph, x, n_edge) fitness_y = Get_fitness(graph, y, n_edge) max_fitness = max(max_fitness, fitness_x, fitness_y) new_group.append((x, fitness_x)) new_group.append((y, fitness_y))
Group = [] for i in new_group: x= Heavy_tailed_mutation(i[0],args.prob_m,graph,n_edge,i[1]) new_fitness=Get_fitness(graph,x,n_edge) max_fitness=max(max_fitness,new_fitness) Group.append((x,new_fitness)) group = Survival_with_fitness(Group, args.size) iterations.append(_) best_results.append(max_fitness) if(_ % 100 == 0): print(_, max_fitness) return iterations, best_results
简而言之,先生成图,而后
选择初始种群
进入迭代
选择杂交父代
交叉遗传
变异
生存选择
下一轮迭代
迭代结束后保存数据
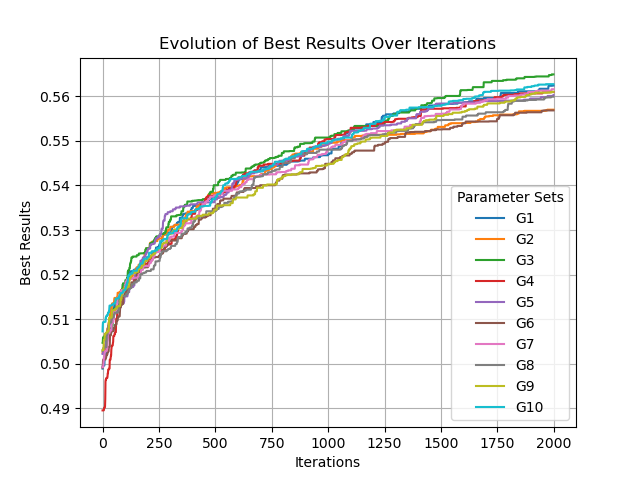
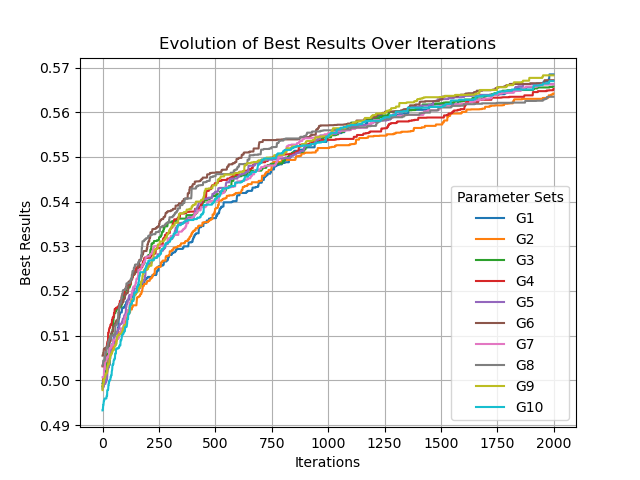
2.3 运行结果
参数选择:
种群size 1
单点变异p=0.001
交叉变异p=0.6
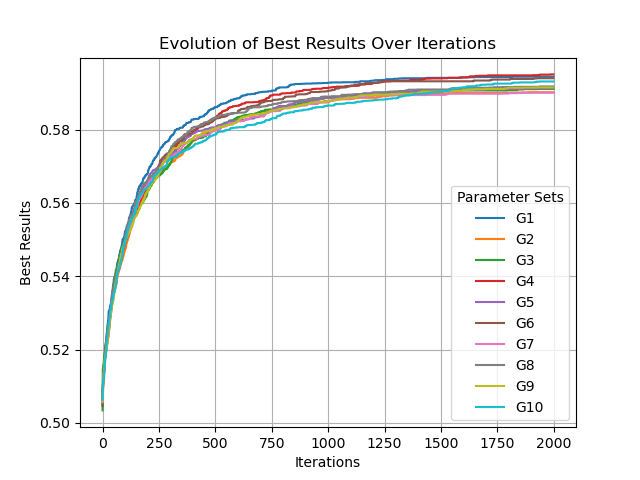
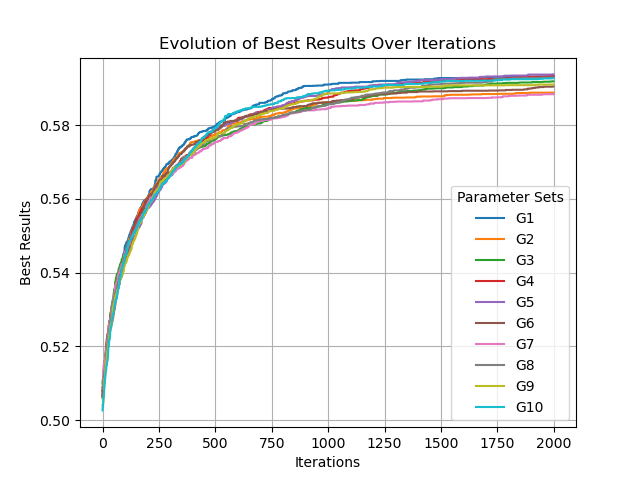
G1→G10
可以看到,fitness不稳定,且未收敛,意味着当前算子和参数的设置还有进步空间。
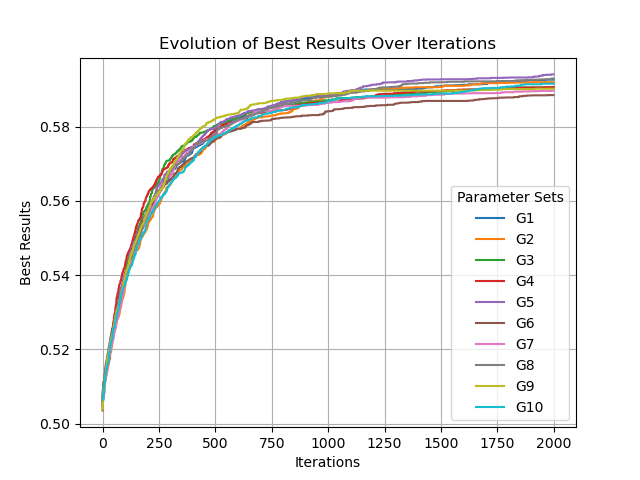
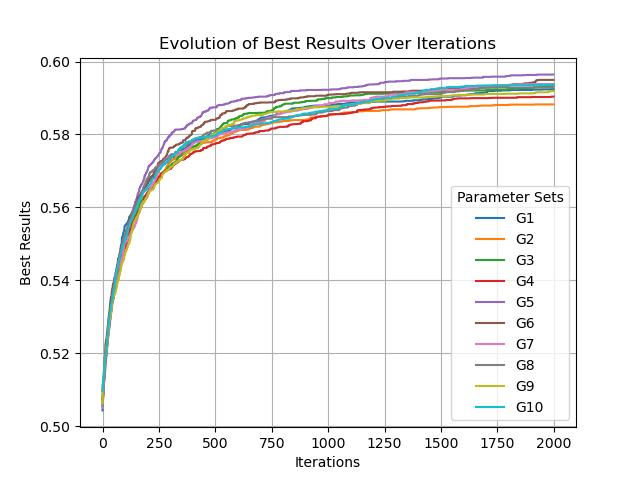
3 任务二 改进变异算子
在tool_box.py中实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
P=[] defInit_P(n): P.clear() B=1.5 sum=0 for i inrange(n//2): sum =sum + (i+1)**(-B) P.append(0) for i inrange(n//2): P.append(((i+1)**(-B))/sum) print(P)
# 三分确定合理的参数取值 l=0.0,r=1.0 while(r-l>1e-5): ll = (r-l)/3 + l rr = (r-l)/3*2 + l if(Performance(ll)>Performance(rr)): l=ll else: r=rr args.ans=ll # then, goto Run_with_different_Graph Function ........
defRun_with_different_graph(args=get_args()): param_sets = [] for i inrange(1, 11): param_sets.append("G"+str(i)) results = [] for i inrange(1, 11): args.gset_id = i iterations, best_results = SEA(args) results.append({'params': param_sets[i-1], 'iterations': iterations, 'best_results': best_results})
for result in results: plt.plot(result['iterations'], result['best_results'], label=str(result['params']))
plt.legend(title='Parameter Sets', loc='lower right') plt.title('Evolution of Best Results Over Iterations') plt.xlabel('Iterations') plt.ylabel('Best Results') plt.grid(True) plt.show()