
Deep_Learning 简介
1. Difference between Deep network and Shollow network
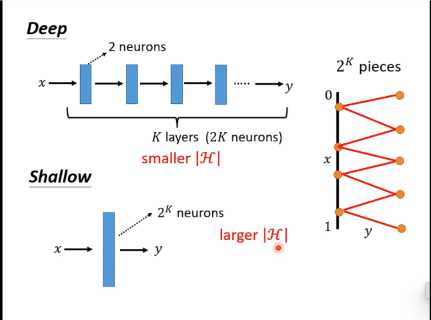
deep network 显著地减少了参数的数量,一方面避免了参数过多而过拟合的风险,一方面也减少了计算量,提高了训练速度。

深度学习可以在参数量小的同时,loss值同样小。做到了鱼与熊掌的兼得。

两难困境
- 模型太大了,理想解恨好,但是训练出来效果不好
- 模型小了,理想和现实接近但是都不好
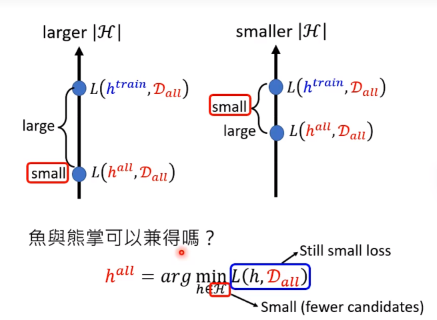
为什么需要Hidden Layer
正常的函数逼近
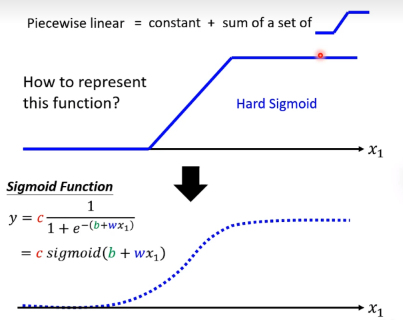
制造很多上图中的sigmoid函数,然后叠加在一起,就可以逼近任何函数了
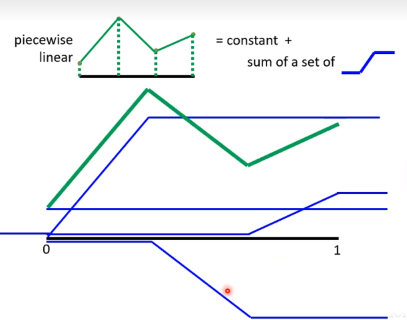
于是通过神经网络的连接,通过设置很多神经元的参数:weight and bios,再通过sigmoid激活函数后组合起来,就可以逼近任何函数了
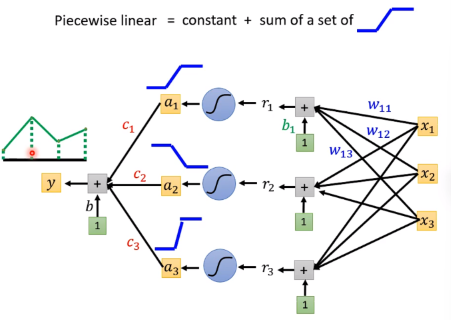
当然更多时候,我们用relu激活函数代替sigmoid函数,因为relu函数更简单,计算量更小,而且效果更好。
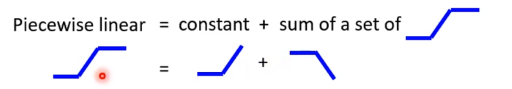
为什么需要多层神经网络
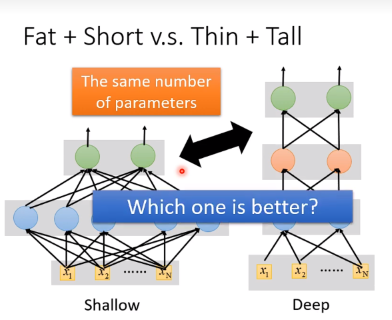
Why we want “Deep” network, while not “fat” network? Just because it sounds cool?
-
Yes, one hidden layer can erpresent any function
-
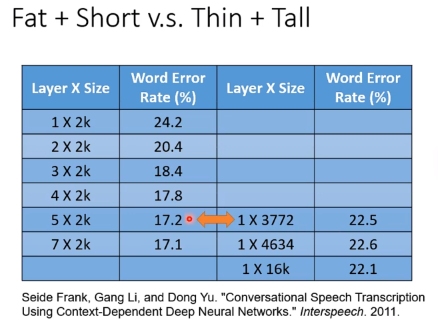
However, using deep structure is more effective.
实际上,deep network需要更少的参数,不容易overfitting。
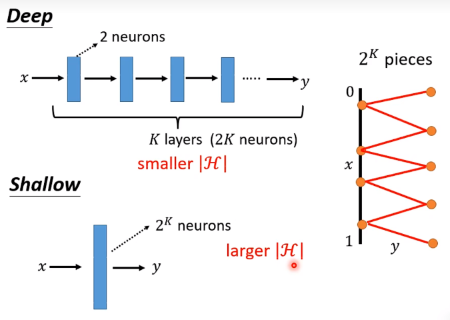
实际上,比如拟合一个函数,使用deep的参数远小于shalow的参数,也就是说如果使用shallow达到和deep一样的效果,参数会非常多,很容易overfitting,为避免overfitting反而需要更多的数据。
所以深度学习适合function复杂且有规律的condition!


All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.