
CNN卷积神经网络-原理
1. 为什么对于图形,不能暴力的使用全连接层?
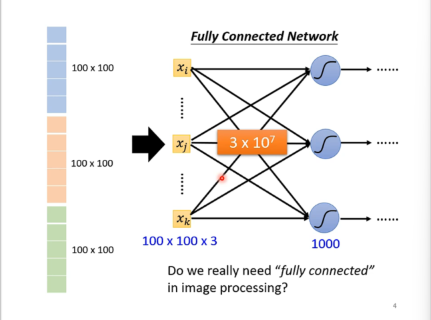
直接全连接,参数过多,训练慢且容易overfitting。
2. 图形识别的一些观察
- 不需要完整的图片,只用看一小部分。
Observation 1
只用在意一个小区域(receptive field)的信息,而不是整张图片。
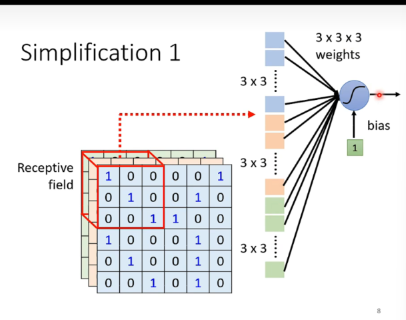
- receptive field可以有重叠甚至可以完全相同(侦测多种pattern)
- receptive field的大小、形状、位置、channal都是可以调整的
Tyopical Setting
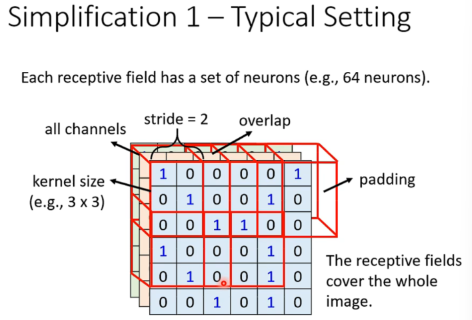
- stride 偏移量
- padding 填充(方法多样
Observation 2
同一个pattern在所有receptive field共享参数。
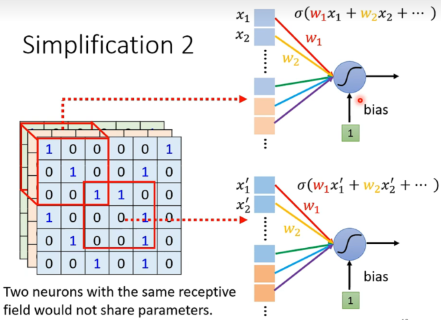
Benefit of Convolutional Layer
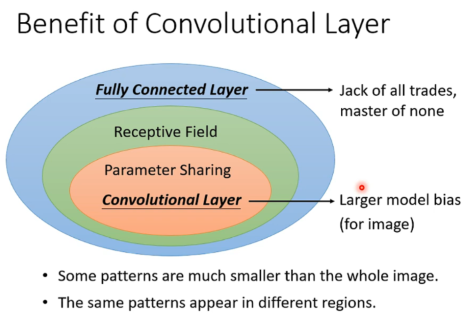
针对图像识别的特化神经网络。虽然弹性变小,但是不会overfitting。
Convolutional Layer
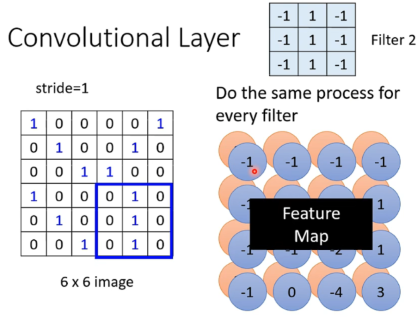
每一个filter都产生一层层特征,所有的filter叠加起来就是一个feature map。
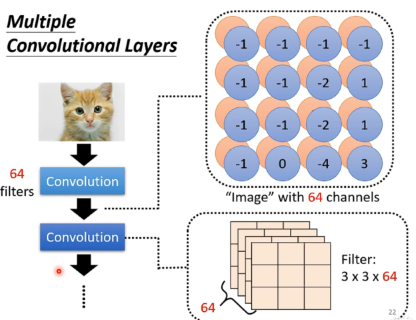
可以发现每个Filter高度等于输入的channel,宽度等于receptive field的宽度。
两种视角看待convolutional layer:

Observation 3
缩放图片不会改变object

Pooling
有很多pooling形式:
- Max pooling
- Mean pooling
一般做完convolutional layer之后,会做一个pooling layer,减少参数。
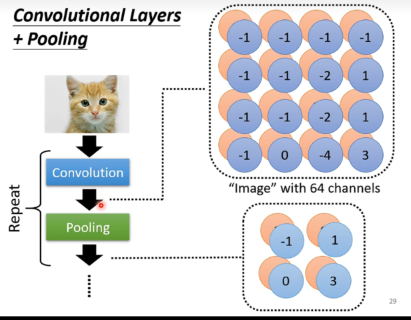
实际实践中,卷积和池化往往会交替进行。
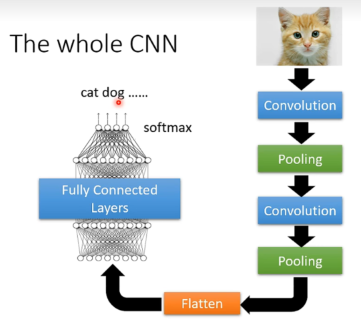
The Whole CNN
处理影像的放大缩小旋转 -> Spatial Transformer Layer
一个可行的解决方案是把数据集也缩放旋转加入训练,但是采用Spatial Transformer Layer可以让神经网络自己学习如何处理这些变化。
CNN is not invariant to scaling and rotation
我们希望有一个神经网络,可以处理不同尺寸的图片,不同角度的图片,不同位置的图片。
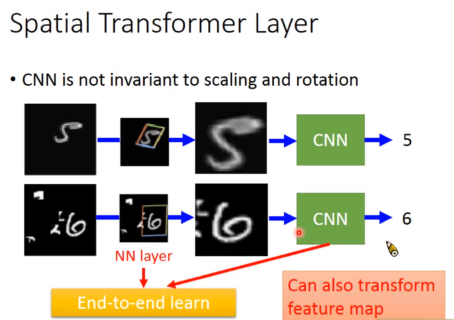
注意,Transformer不仅作用在原图片,也可以作用在feature map上。
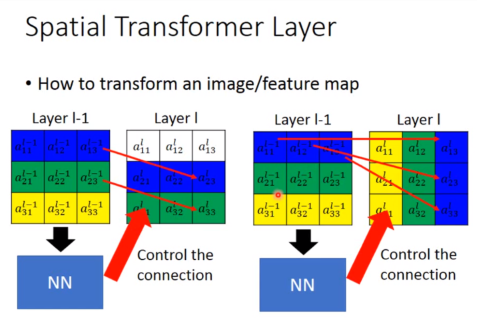
做到旋转缩放原理
实际上就是简单的线性代数。
设置一个theta矩阵,然后对原图片进行仿射变换。
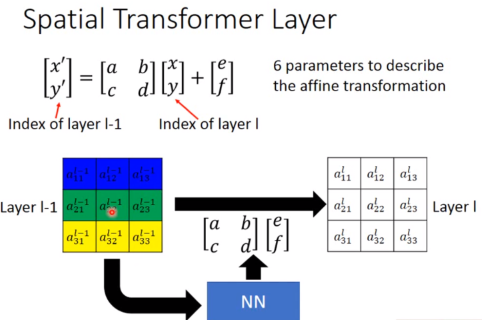
添加6个参数,可以做到图像的旋转缩放。
对于变化后的pixel,如果不是整数可以采用Interpolation的方法。(双线插值)
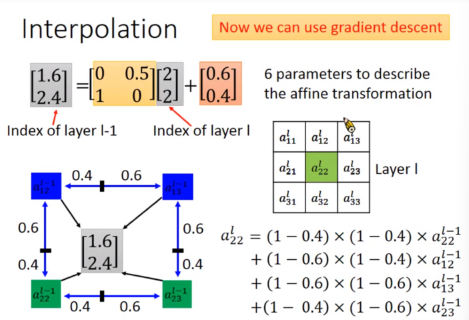
于是又可以愉快地使用gradient descent解了。
流程长这样:
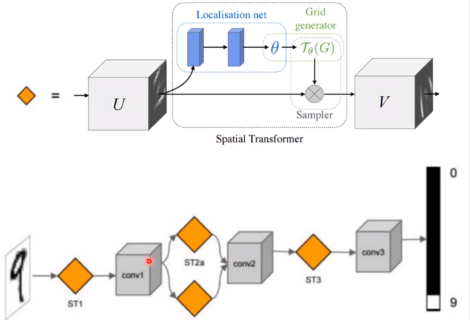
效果图:
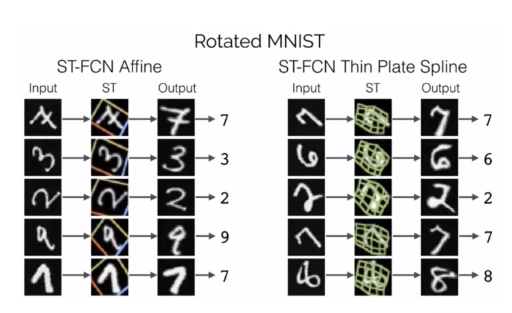
实际例子:
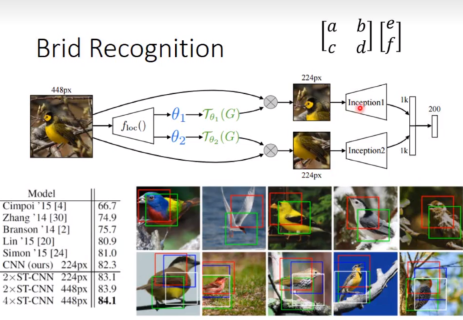
通过了两个Transform,分别放大了鸟的嘴和身体。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.