
浅析Alpha-Go
浅析Alpha-Go
detect0530@gmail.com
训练&执行步骤

先找很多对局素材,进行监督学习,然后分别训练policy和value network。
最后再依据policy和value函数进行蒙特卡洛树搜索。
Policy Network
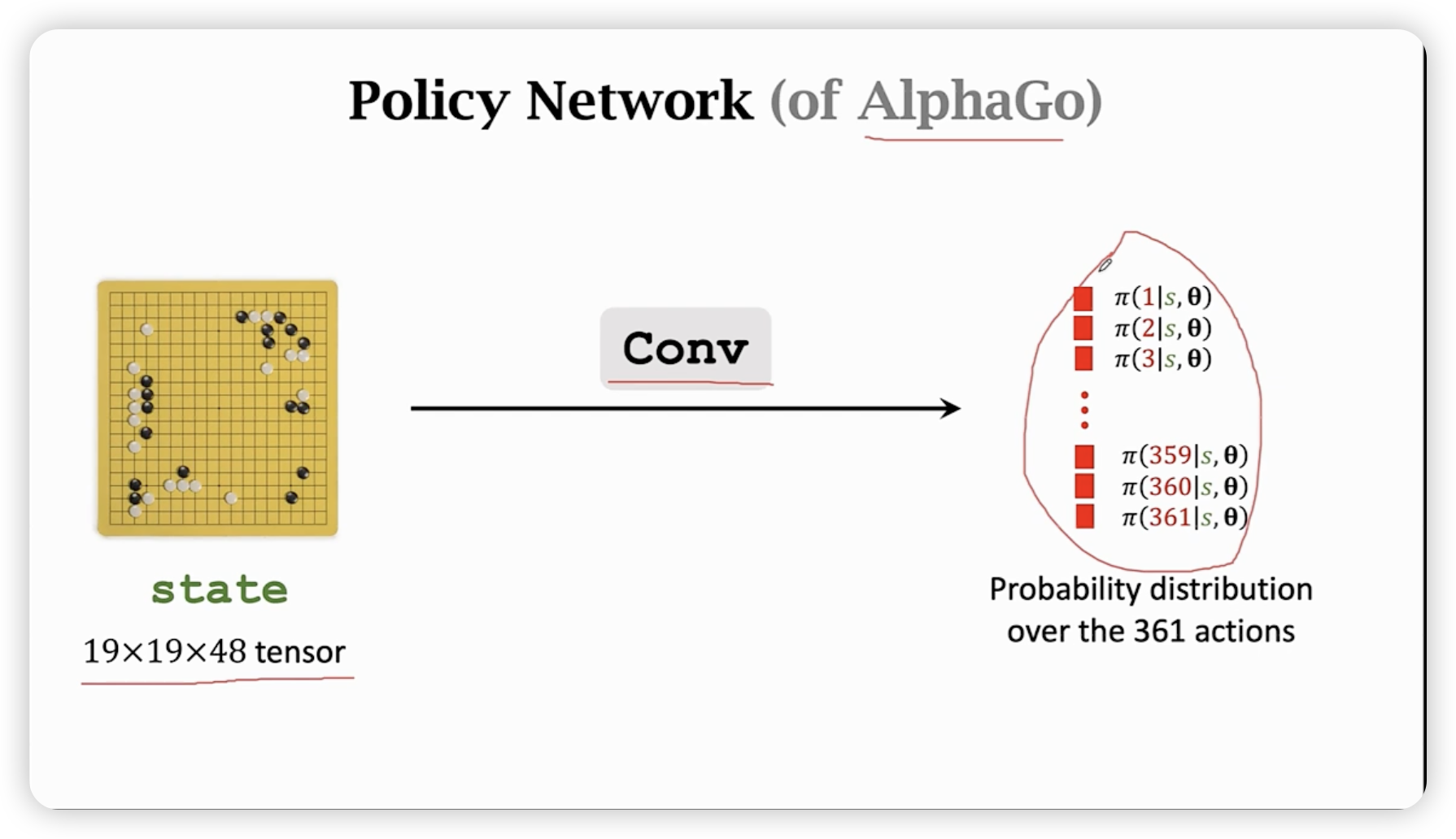
通过191948的tensor表示状态,然后用convolutional layer提取特征,最后用softmax输出每个动作的概率。(361个动作)
一开始先用人的对局用来学习初步的策略网络。

用behavior cloning的方法(imitation learning 与reinforcement learning区别在于有无reword),让policy network去模仿人的对局。

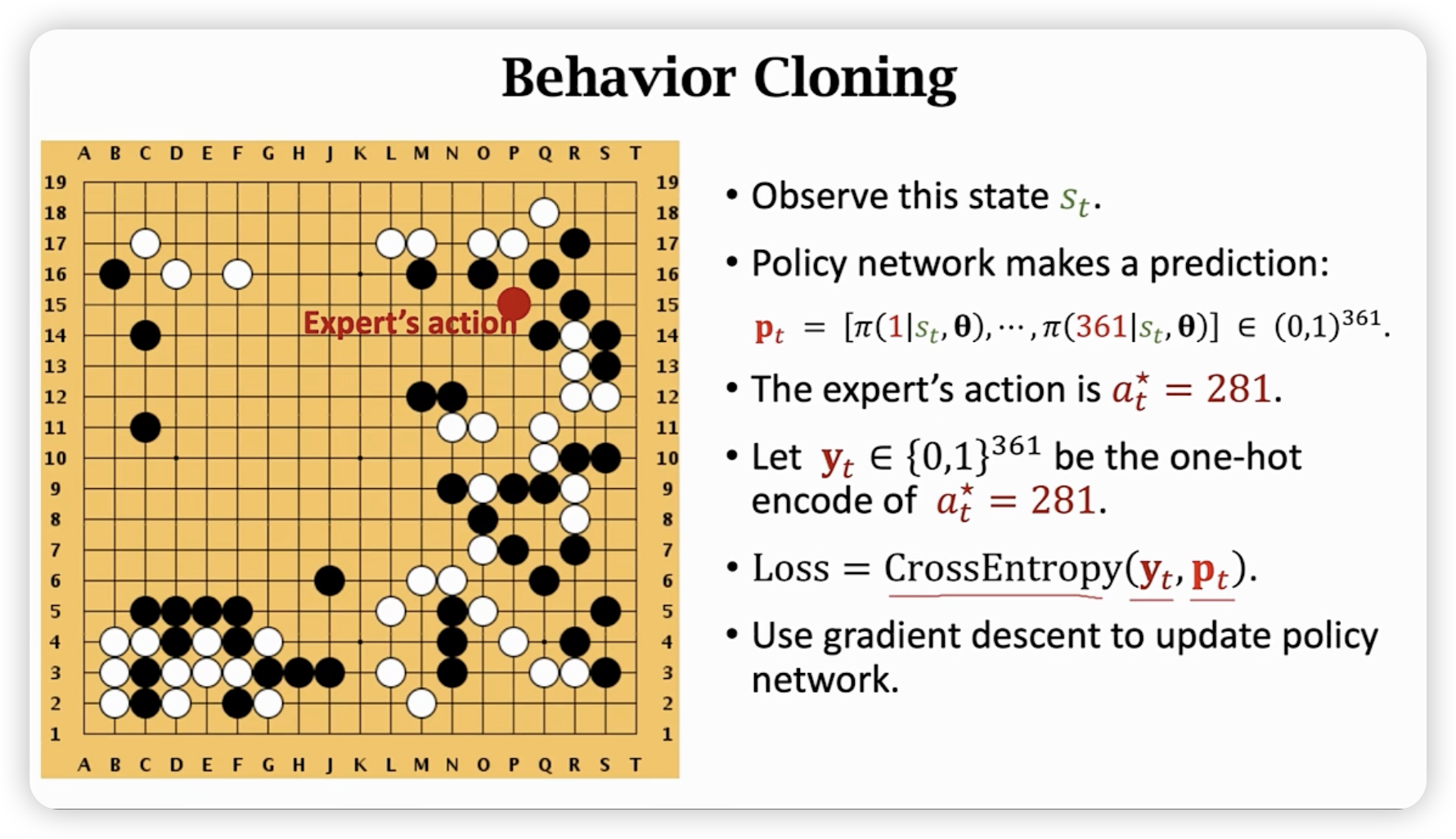
其实就是一个交叉熵作为loss function的多分类问题。
Behavior cloning缺点是效果不好,没见过的话,不知道怎么走。
所以我们需要用reinforcement learning来改进behavior cloning训练出的policy network。
Train Policy network using policy gradient
Policy network

用更早的参数作为opponet(当作环境交互)的policy network参数。

赢了就每一步都是好棋。

这里的要么是1要么是-1。

反复迭代后,策略网络就训练好了。
Value network
这时,policy network已经可以和人类高手对战了,很强,但是不够强。
其表现不太稳定,一个小的错误也许就会输掉比赛。
由此,我们还需要改进。使用蒙特卡洛树搜索来让结果更稳定。
而,蒙特卡洛树搜索需要value network来评估局面。

注意,这里的价值函数近似的是V函数评估状态的好坏,而不是之前的Q函数评估状态和动作的好坏。
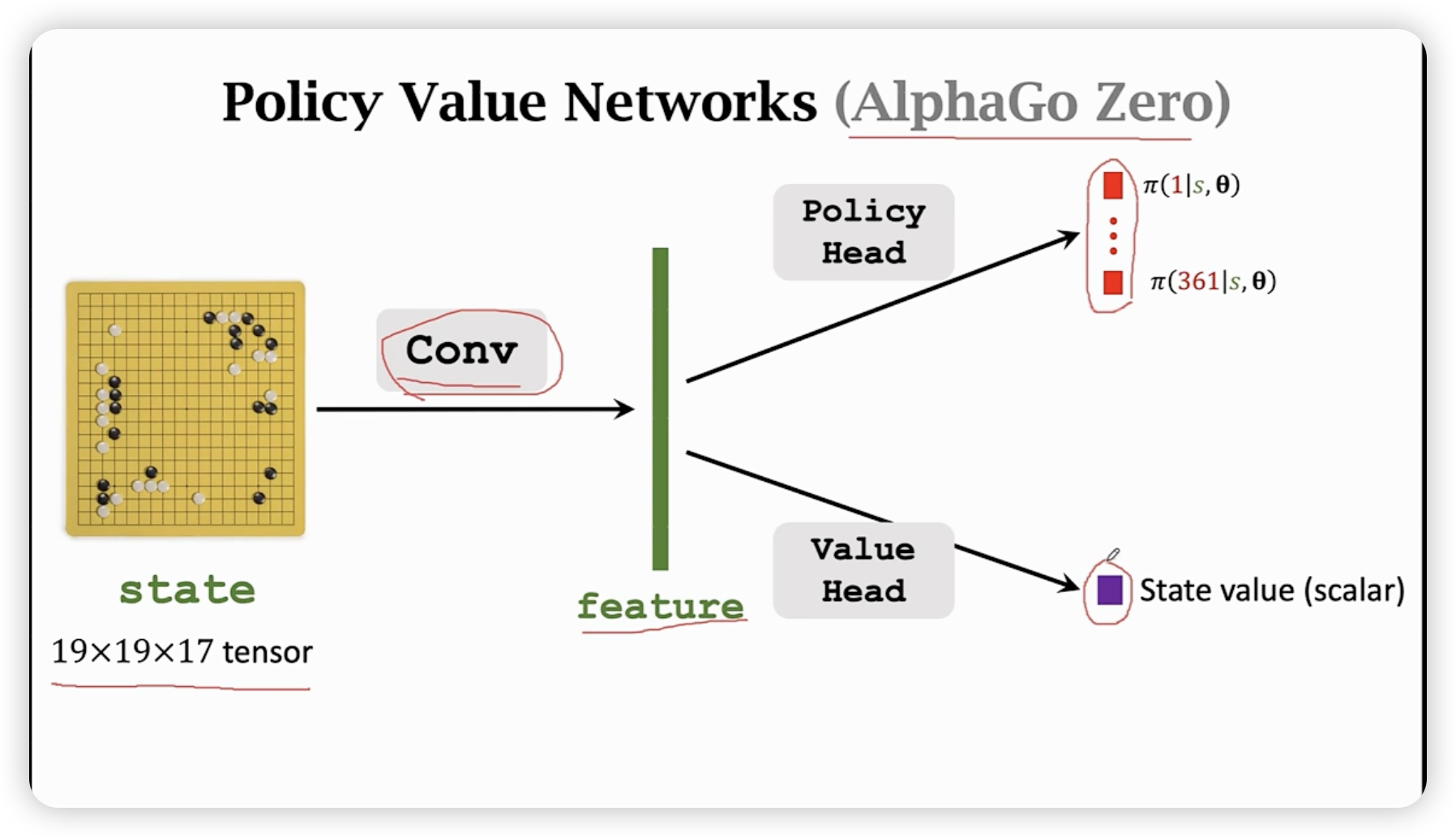
价值网络是由训练好的策略函数辅助训练。

利用反复自我博弈,依据policy network下棋,然后标记每一个状态的好坏,用去训练value network。
Monte Carlo Tree Search
用策略函数按照概率选择下一步走什么(不好的走法没必要浪费资源去搜索),然后反复这样自我博弈看谁会赢。最后选择一个最高得分的action。

分步骤来看:





可以发现,如果一个action被探寻足够多,在后期函数的影响会被分母抵消,变相说明action的Q(a)价值很高,值得我们选,在探寻小的时候,函数的影响很大,策略函数本就是较优的,也会选出比较好的解。
每走一步,会按照以上四步进行上万次模拟。
搜索结束后,我们选择N(action)最大的那个action即可。
Summary

AlphaGo Zero v.s. AlphaGo
- 完胜AlphaGo
- 没有使用human experence (也许人类知识是有害的)
- 使用MCTS去训练policy network,让策略网络模仿MCTS的结果,而不是人类的对局。
